集群使用指南

从0到1在学校Top500超算集群跑HPL程序
✅ 温馨提醒
你可以通过这个视频,主要介绍了底层系统知识、集群作业调度系统、容器和环境的基础知识。提到了多线程技术可以提高计算效率,如通过并行计算将任务分配到不同的CPU上进行计算。此外,还介绍了启明平台的基本结构和资源,包括CPU节点、内核之间的通信、NUMA结构等。最后,提到了一些相关的工具和库,如MPI、Java编译器、矩阵处理、线性代数函数库等。还在学校曾经的Top500超算集群上编译和运行了HPL程序。
超算集群介绍
什么是超级计算机?
“超算”即“超级计算”或“超级计算机”(Supercomputing / Supercomputer),是专为处理大规模、高性能科学计算任务而设计的计算平台。它们通常具备远超普通计算设备的算力,广泛应用于气象模拟、分子动力学、基因组学分析等对计算资源要求极高的领域。
传统上,超级计算机的性能以每秒浮点运算次数(FLOPS)为主要衡量标准。然而,随着计算需求的多样化与可持续发展的重视,单一的 FLOPS 指标已不再全面,业界也逐渐引入了包括存储访问速度、能效比(如碳排放水平)等多维度的评估指标。
目前,全球最具权威性的超级计算机性能排名是 Top500 榜单。我国的「神威」与「天河」等系统曾多次上榜,而我校自研的「太乙」集群也曾于 2018 年入选该榜单,位列第 127 位,展现出强劲的自主计算能力。
超级计算机用来解决什么问题?
超级计算机最初的诞生是为了解决那些对计算能力要求极高、数据规模庞大、求解过程极其复杂的科学与工程问题。随着计算技术的不断演进,超级计算机也经历了从同构集群向异构集群的架构转型,逐步在多个领域发挥出越来越广泛和深远的作用。
按笔者的理解,超级计算机的典型应用场景主要可以归纳为以下三个方向:
- 科学研究类问题
- 🌀 气候与气象模拟 「进阶赛道:WRF气象模拟挑战」
- 🧬 分子模拟与药物设计
- 🧫 基因组学与生命科学
- 🌌 天体物理与宇宙模拟
- 🏗 结构力学与流体力学 「基础赛道:CloverLeaf 编译优化挑战」
- 🔐 密码破解与安全通信 「基础赛道:Rust LWE 编程挑战」
- 人工智能与大数据
- 🧠 深度学习训练 「进阶赛道:DiT图像生成挑战」
- 🗺 图神经网络与复杂系统建模 「进阶赛道:GEMM编程挑战」
- 量子计算机
- ⚛ 与量子计算机结合的混合计算研究 「基础赛道:量子计算模拟编程挑战」
因此,学习和使用超级计算机并非计算机专业学生的“专利”。它对来自不同学科背景、具有多样研究问题的科研人员同样开放与重要。例如,我校陈晓非教授课题组于 2017 年凭借“非线性地震模拟”项目,荣获高性能计算领域最具影响力的“戈登·贝尔奖”,该项目正是建立在超级计算平台之上的跨学科研究典范。
超级计算机 101
超级计算机,说白了就是一台超大号、超快版的计算机。它不是我们日常用的笔记本或台式机,而是由成百上千颗高性能处理器、海量存储设备和高速网络连接组合在一起的庞大系统。
从硬件角度来看,你可以把它理解成三大部分:
- 🧠 计算单元:也就是一堆非常强的“芯片”或“处理器”。它们可以是多核 CPU、高性能 GPU,甚至是更专业的加速器(比如 AI 芯片),专门用来同时做很多复杂的计算。
- 💾 存储系统:类似“超级硬盘”,用来保存你要处理的大量数据,比如天气模型、分子结构、图像数据等。超级计算的数据可能是以 TB、PB 甚至更高为单位的。
- 🌐 高速网络:这些芯片和存储设备不是靠“插根网线”就能连在一起的,它们之间需要靠一种非常快的“通信高速公路”来交换数据,速度比普通家用网络快成千上万倍。
但光有硬件是不够的,想让这么庞大复杂的系统正常运转,还需要一整套软件系统来协调调度:
- 🧭 操作系统:就像超级计算机的大脑,负责管理各个部分,保证它们可以互相配合(比如 Linux)。
- 🛠️ 并行编程环境:要让几千个计算核心“同时干活”,我们得用一些专门的工具和方法来告诉它们怎么分工协作,比如 MPI、OpenMP、CUDA 等。这就像一支上千人的施工队,每个人要知道自己的任务。
- 📋 作业调度系统:每个用户提交的计算任务都要排队分配资源,谁先做、在哪做、做多久,全靠调度系统来安排。常见的调度系统有 Slurm、PBS 等。(后面会详细讲)
使用超级计算机我需要掌握什么?
想要上手使用超级计算机,不需要你一开始就是顶级程序员,但掌握一些基本技能是非常必要的。下面是你需要了解的几个关键方面:
远程访问超级计算机:
ssh超级计算机通常部署在机房或数据中心,用户需要通过远程登录的方式访问它。你需要学会使用
ssh命令,从自己的电脑连接到超算服务器,就像“连线”进入另一个计算世界。Linux 基本指令与 Shell 脚本编写
超级计算机大多运行的是 Linux 系统,所以你需要了解一些基础命令,比如
ls(查看文件)、cd(切换目录)、cp(复制文件)等。此外,写一两个简单的 Shell 脚本,可以帮助你自动化提交任务、批量处理数据,提高效率。环境管理与配置
不同的程序、库和依赖会存在不同版本,为了让你的代码能在超算上顺利运行,你需要学会使用环境管理工具(如
module、conda、venv等)来配置运行环境。使用作业管理系统
超算资源是多人共享的,不能像自己电脑一样随意运行程序。你需要将任务写成“作业脚本”,提交给调度系统(如 Slurm),让系统根据资源情况安排运行。掌握如何写作业脚本、查看队列、监控状态是关键技能。
编程技能:高性能优化的奇技淫巧【进阶】
如果你希望充分发挥超算的威力,你可以进一步学习并行编程(如 MPI、OpenMP、CUDA)、算法优化、向量化编程等技巧,提升程序运行效率,让它“飞”起来。
✅ 小贴士
初学者不必一步到位,只要掌握前四项,就已经可以在超算平台上顺利运行自己的程序了!后续可以根据项目需要,逐步深入高性能优化的世界
📑 学习资料
这些基础内容的学习,笔者推荐可以参考MIT的线上课程:计算机教育中缺失的一课,会带你至少Cover前三个最基本的内容,如果觉得课程内容过多,希望能够亲自上手实践,笔者推荐各位可以前往 超算习堂,并在实训环境中锻炼自己的基础技能
超级计算机的常见配置
通常来说,超级计算机的配置会分为:登录节点、计算节点和存储节点,有的对应管理员还会设置专门的管理节点,不同的超级计算机集群的架构都不同,提前阅读超级计算机集群的结构会让你更清楚你有什么资源可以调用,评估是否满足自己的运算需求。不同节点的节点配置会略有不同:
| 节点类型 | 主要作用 | 常见配置特点 | 用户是否可直接使用 |
|---|---|---|---|
| 登录节点 | 用户登录入口、任务准备与提交 | - 少量高频 CPU - 适度内存 - 多用户共享 - 安装常用软件工具 | ✅ 是,通常通过 ssh 登录 |
| 计算节点 | 实际执行计算任务 | - 高性能多核 CPU / GPU - 大内存 - 支持并行计算 - 无图形界面 | 🚫 否,通过作业系统调度访问 |
| 存储节点 | 负责读写与管理大规模数据 | - 大容量磁盘阵列 - 高速 I/O 接口(如 InfiniBand) - 数据备份机制 | 🚫 否,由系统统一管理,不直接登录 |
| 管理节点(可选) | 管理任务调度、资源分配、监控系统 | - 运行作业调度器(如 Slurm) - 控制集群资源调度与运行状态 | 🚫 否,管理员专用 |
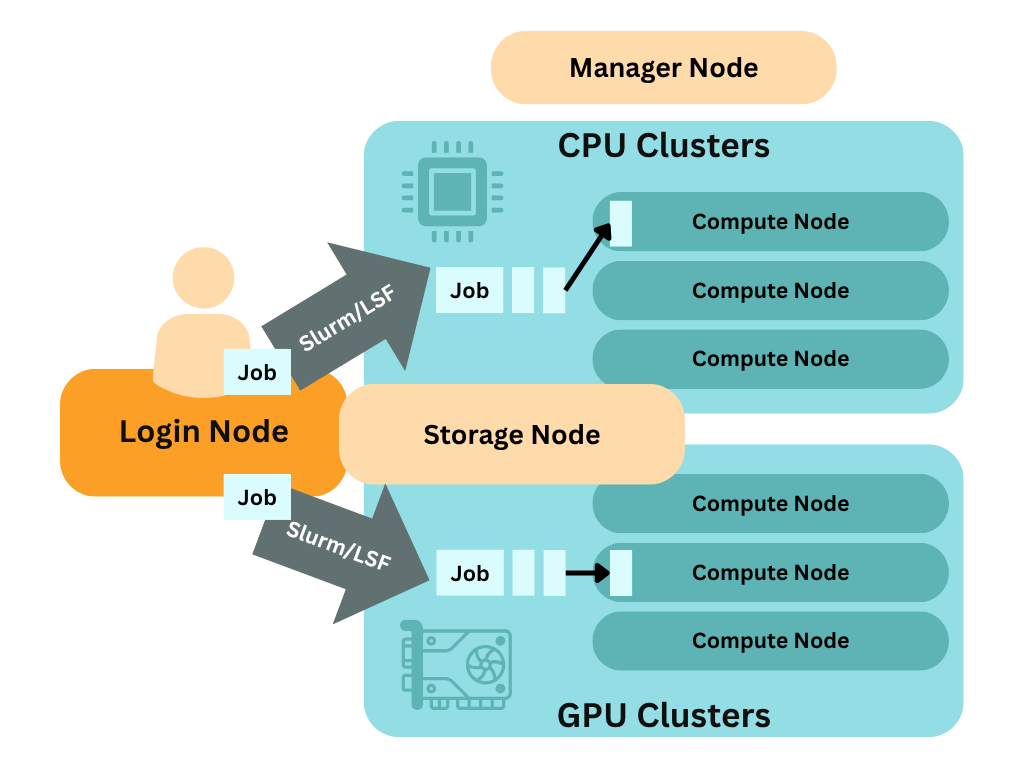
✅ 补充说明
- 🧩 登录节点 ≠ 计算节点:你在登录节点上做准备工作(如代码编译、作业提交),而真正的计算会被作业调度系统分配到计算节点上执行。通常来说,在自己的用户目录下,登录节点和计算节点的路径会保持一致,但是具体的环境会有所不同,在配置环境时要注意是否能否兼容计算节点的配置。
- 💾 存储节点一般与用户的工作目录挂载在一起,支持高并发访问,适合存储输入/输出数据、临时文件或结果文件。
作业调度系统
在超级计算机上,资源总是有限的,而用户和任务却可能成百上千。这时,作业调度系统(Job Scheduler)就成为整个高性能计算平台的“总指挥官”,它负责接收用户任务、评估资源情况,并高效地将任务安排到适当的计算节点上执行。
调度系统是用来?
作业调度系统的核心价值在于资源的高效利用与公平分配。在没有调度系统的情况下,用户可能会争抢资源、任务冲突频发,最终导致计算资源被大量浪费或长时间闲置。而有了调度系统之后,它可以:
- 保证每个任务按规则排队执行(先来先服务、优先级、高通量等)
- 支持任务并行、分布式执行
- 合理预估资源占用,防止系统过载
- 自动记录任务状态与日志,便于用户跟踪与管理
常见的调度器系统
目前主流的调度器有:
- Slurm(Simple Linux Utility for Resource Management):目前使用最广泛的开源调度系统,广泛用于高校、科研机构与国家超算中心
- PBS / Torque:较早的调度系统之一,许多老牌集群仍在使用
- LSF、LoadLeveler、HTCondor 等:多用于企业、商业场景或特定科研机构,启明和太乙使用的便是LSF作业调度系统
其中 Slurm 以其模块化、可扩展、文档完善的特点,在学术界和工程界都有非常高的采用率。
Slurm 使用流程
本次校内超算竞赛平台采用的调度系统为Slurm,Slurm的官方指南请查看这里,我们在这里将会简单介绍Slurm的使用方式,Slurm的常用指令有:
| 命令 | 中文说明 |
|---|---|
sacct | 用于查询作业或作业步骤的账务信息,包括正在运行或已完成的作业。 |
salloc | 用于实时分配资源给一个作业。通常用于分配资源后启动一个交互式 Shell,用户可以在这个 Shell 中使用 srun 启动并行任务。 |
sattach | 用于连接到一个正在运行的作业或作业步骤,附加标准输入、输出、错误流以及信号处理功能。可多次连接或断开。 |
sbatch | 用于提交一个作业脚本以便稍后执行。脚本通常会包含一个或多个 srun 命令来启动并行任务。 |
scancel | 用于取消一个等待中或正在运行的作业或作业步骤。也可以用于向作业相关进程发送特定信号。 |
sinfo | 用于查看 Slurm 管理的分区(partition)和节点状态。支持多种过滤、排序和格式化选项。 |
squeue | 用于查看作业或作业步骤的状态。支持多种筛选、排序和格式化选项。默认按照优先级显示运行中的作业,然后是等待中的作业。 |
srun | 用于立即提交一个作业或启动作业步骤。支持大量资源指定选项,包括:最小/最大节点数、CPU 数量、指定使用或排除的节点、节点特性(内存大小、磁盘空间、功能标签等)。一个作业可以包含多个串行或并行的作业步骤,分别在共享或独立资源上运行。 |
通常来说,我们会选择在登录撰写作业脚本 job.slurm 并通过 sbatch 将作业提交到对应的队列中,可以使用的队列可以通过 sinfo 来查看,下面是一个提交到CPU队列的Slurm脚本案例:
#!/bin/bash
#SBATCH --job-name=cpu_job_test # 作业名称
#SBATCH --partition=cpu # 提交到 CPU 队列(partition 名)
#SBATCH --nodes=1 # 所需节点数
#SBATCH --ntasks=1 # 总任务数(通常 = 核心数)
#SBATCH --cpus-per-task=4 # 每个任务使用的 CPU 核心数
#SBATCH --time=02:00:00 # 最长运行时间(格式:hh:mm:ss)
#SBATCH --output=cpu_job_%j.out # 标准输出日志(%j 会替换为作业ID)
#SBATCH --error=cpu_job_%j.err # 标准错误日志
# 加载所需的模块(根据你平台的 module 系统)
module purge
module load gcc/9.3.0
module load python/3.10
# 或者通过设置环境变量来配置环境
export PATH=$PATH:/work/user/bin
export LIBRARY_PATH=$LIBRARY_PATH:/work/user/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/work/user/lib
# 显示环境信息
echo "Job started on $(hostname) at $(date)"
echo "Running on CPU with $SLURM_CPUS_ON_NODE cores"
# 执行你的程序(示例为 Python 脚本)
python my_cpu_program.py
echo "Job finished at $(date)"比赛使用集群配置
队列信息
| 队列名称 | 内存 | CPU类型 | GPU类型 | 节点数 |
|---|---|---|---|---|
| 8175m | 196GB | Intel Xeon Platinum 8175M @ 2.50GHz | - | 27 |
| 8v100-32 | 32GB * 8 | Intel Xeon Platinum 8255C @ 3.80GHz | 8 * Tesla V100 32GB | 1 |
CPU配置
8175m队列的CPU配置为Intel Xeon Platinum 8175M @ 2.50GHz,具有48个核心和196GB内存。该队列适合需要较大内存和多核计算的任务。更多细节请查看官网。
| Category | Specification |
|---|---|
| Architecture | x86_64 (64-bit, Little Endian) |
| CPU Model | Intel Xeon Platinum 8175M @ 2.50GHz |
| Cores/Threads | 2 Sockets × 24 Cores = 48 Total CPUs |
| Clock Speed | 2.5 GHz (Base) |
| Cache | L1d: 32KB/core, L1i: 32KB/core |
| L2: 1MB/core, L3: 33MB total (shared) | |
| NUMA | 2 Nodes (CPU 0-23, 24-47) |
| Virtualization | VT-x supported |
| ISA Extensions | AVX-512, AES-NI, SSE4.2, RDRAND, TSX, etc. |
GPU配置
8v100-32队列的GPU配置为8张Tesla V100 32GB GPU,适合需要高性能计算和大规模并行处理的任务。更多细节请查看白皮书。
| Property | Specification |
|---|---|
| GPU Architecture | Volta (GV100) |
| FP32 Performance | ~15 TFLOPS (SXM2) / ~14 TFLOPS (PCIe) |
| FP64 Performance | ~7.5 TFLOPS (SXM2) / ~7 TFLOPS (PCIe) |
| Tensor Cores | 640 (for mixed-precision AI workloads) |
| Memory (VRAM) | 32GB HBM2 (ECC supported) |
| Memory Bandwidth | 900 GB/s |
| Memory Interface | 4096-bit bus |
| CUDA Cores | 5120 |
| Boost Clock | ~1530 MHz (SXM3) / ~1380 MHz (PCIe) |
| TDP | 300W (SXM3) / 250W (PCIe) |
集群拓扑
| GPU | GPU0 | GPU1 | GPU2 | GPU3 | GPU4 | GPU5 | GPU6 | GPU7 | NIC0 |
|---|---|---|---|---|---|---|---|---|---|
| GPU0 | X | NV2 | NV2 | NV1 | NV1 | SYS | SYS | SYS | SYS |
| GPU1 | NV2 | X | NV1 | NV2 | SYS | NV1 | SYS | SYS | SYS |
| GPU2 | NV2 | NV1 | X | NV1 | SYS | SYS | NV2 | SYS | PIX |
| GPU3 | NV1 | NV2 | NV1 | X | SYS | SYS | SYS | NV2 | PIX |
| GPU4 | NV1 | SYS | SYS | SYS | X | NV2 | NV2 | NV1 | SYS |
| GPU5 | SYS | NV1 | SYS | SYS | NV2 | X | NV1 | NV2 | SYS |
| GPU6 | SYS | SYS | NV2 | SYS | NV2 | NV1 | X | NV1 | SYS |
| GPU7 | SYS | SYS | SYS | NV2 | NV1 | NV2 | NV1 | X | SYS |
| NIC0 | SYS | SYS | PIX | PIX | SYS | SYS | SYS | SYS | X |
- NV1/NV2: NVLink连接
- PIX: PCIe连接
- SYS: 系统层级的PCIe链接,会慢于PCIe连接
✅ 拓扑结构说明
- NVLink连接分组
- Group 0(GPU0–GPU3):组内通过高速NVLink(NV1/NV2)互联(NV2速度更快),绑定到NUMA Node 0。
- Group 1(GPU4–GPU7):组内同样通过NV1/NV2高速互联,绑定到NUMA Node 1。
- 跨组连接
- Group 0和Group 1之间仅通过PCIe(SYS)通信(如GPU0-GPU4),速度较慢。
- 避免跨组多GPU任务,否则性能会受PCIe带宽限制。
- 网卡(NIC0)连接
- 直接通过PCIe(PIX)连接到GPU2/GPU3,说明这两张GPU适合网络密集型任务(如分布式训练)。
常用Linux指令
基础配置与系统信息
lscpu # 查看CPU配置信息
nvidia-smi # 查看GPU使用情况
nvidia-smi topo -m # 查看GPU拓扑结构
top # 实时查看进程和系统负载
htop # 更友好的进程和资源监控(部分系统需自行安装)
free -h # 查看内存使用情况
uname -a # 查看操作系统内核信息
cat /proc/cpuinfo # 查看详细CPU信息
cat /proc/meminfo # 查看详细内存信息存储与磁盘空间
ls -lah # 查看当前目录下文件和大小
df -h # 查看磁盘分区挂载和剩余空间
du -h --max-depth=1 # 查看当前目录下各子目录大小
find . -name "*.out" # 查找当前目录下所有 .out 文件文件与目录操作
cp source.txt dest.txt # 复制文件
mv oldname.txt newname.txt # 重命名或移动文件
rm file.txt # 删除文件
rm -r dir/ # 删除目录及其内容
mkdir newdir # 新建目录
tar -czvf archive.tar.gz dir/ # 打包并压缩目录
tar -xzvf archive.tar.gz # 解压 tar.gz 文件网络与远程
ssh user@hostname # 远程登录
scp file.txt user@host:/path/ # 远程拷贝文件到服务器
wget http://url/file # 下载文件软件与环境
module avail # 查看可用的软件模块
module load gcc/9.3.0 # 加载指定版本的软件模块
module list # 查看当前已加载模块
conda activate myenv # 激活conda环境(如有安装)作业管理(Slurm)
squeue # 查看作业队列
sinfo # 查看分区和节点状态
sacct # 查询作业历史和资源使用
sbatch job.slurm # 提交作业脚本
scancel <jobid> # 取消作业
srun hostname # 交互式运行命令太乙与启明
南方科技大学及CCSE简介
南方科技大学(SUSTech)于2011年2月2日正式成立,是一所坐落于中国深圳经济特区的公立大学。学校致力于成为一所在交叉学科研究、创新人才培养和前沿知识创造方面具有国际影响力的顶尖学府。为培养具备高性能计算技术能力的学生并推动计算密集型科研发展,南科大于2015年成立了超算中心(现称"计算科学与工程中心",CCSE),并与浪潮、联想签署战略合作协议共建高性能计算平台。

超算相关硬件与软件平台
南方科技大学计算科学与工程中心的高性能计算平台包含本地计算平台和云平台两部分。本地计算平台由"太乙"和"启明"两套集群组成。
目前平台CPU核心总数已达43,136个,GPU卡总数达38张(含10张V100和28张A100)。平台整体双精度计算能力超过3.5 PFlops,存储裸容量总计6.6 PB。
太乙集群

太乙集群包含815个双刀片节点、2个大内存节点和4个GPU节点,采用Intel Omni-Path高速计算网络(100 Gbps OPA),存储裸容量5.5 PB,实测写入I/O带宽超过45 GB/s,读取I/O带宽超过60 GB/s。
2018年12月,南科大二期HPC平台"太乙"(见上图)正式投入运行。该系统拥有约820个计算节点、4万核心和4.0 PB存储空间,实测浮点计算性能达1.6 Pflops。在2018年11月的全球超算TOP500榜单中排名第127位,在2018年10月中国超算TOP100榜单中排名第39位。
太乙软件配置
| 操作系统 | Rocky Linux 8.6(Green Obsidian) |
|---|---|
| 集群并行环境 | Intel MPI-2018 |
| Open MPI-3.1.2 | |
| 集群开发环境 | GNU C/C++编译器 |
| CUDA Toolkit 10.0 | |
| Intel MKL数学核心库 |
太乙硬件配置
| 队列 | 核心数 | 内存 | CPU类型 | GPU类型 | 运行时限(小时) | 节点数 |
|---|---|---|---|---|---|---|
| large | 40 | 192g | 第一代至强可扩展 | - | 36.00 | 815 |
| medium | 40 | 192g | 第一代至强可扩展 | - | 72.00 | 815 |
| short | 40 | 192g | 第一代至强可扩展 | - | 144.00 | 815 |
| ser | 40 | 192g | 第一代至强可扩展 | - | 168.00 | 815 |
| debug | 40 | 192g | 第一代至强可扩展 | - | 0.33 | 815 |
| gpu | 40 | 384g | 第一代至强可扩展 | 2*v100 16g | 168.00 | 4.00 |
| spec | 40 | 192g | 第一代至强可扩展 | - | 无限制 | - |
| smp | 192 | 6t | 第一代至强可扩展 | - | 168.00 | 2.00 |
启明2.0集群
2022年升级后,启明集群已扩展至269个刀片节点、12个大内存计算节点和7个GPU节点,采用Mellanox EDR高速计算网络(100 Gbps IB),存储裸容量1.1 PB,实测写入I/O带宽超过45 GB/s,读取I/O带宽超过90 GB/s。

随着科研快速发展,对资源分配和设备管理的需求日益增长。2016年6月,南科大获得首期HPC集群"启明"。该平台由浪潮集团建设,系统实测峰值超过200 Tflops,位居国内高校前列。系统包含刀片节点、胖节点和GPU节点,含4个登录节点和2个管理节点。存储系统采用IEEL并行文件系统,计算网络采用Mellanox EDR 100 Gbps InfiniBand。值得一提的是,启明是当年国内首个采用Mellanox EDR 100 Gbps InfiniBand的超算系统。
启明2.0软件配置
| 操作系统 | Rocky Linux 8.6(Green Obsidian) |
|---|---|
| 集群并行环境 | Intel MPI-2021.7.0 |
| Open MPI-4.1.2 | |
| 集群开发环境 | Intel Parallel Studio XE 2021 |
| NVHPC/22.11 | |
| GNU C/C++编译器 | |
| CUDA Toolkit 11.8 | |
| Intel MKL数学核心库 |
启明2.0硬件配置
| 队列 | 核心数 | 内存 | CPU类型 | GPU类型 | 时限(H) | 节点数 |
|---|---|---|---|---|---|---|
| spec-cpu | - | - | - | - | 无限制 | - |
| 38 | 64 | 512g | 第三代至强可扩展 | - | 720 | 36 |
| 33 | 40 | 192g | 第一代至强可扩展 | - | 720 | 68 |
| ot38 | 64 | 2t | 第三代至强可扩展 | - | 336 | 1 |
| 2t50c | 64 | 2t | 第三代至强可扩展 | - | 336 | 4 |
| 1t75c | 64 | 1t | 第三代至强可扩展 | - | 336 | 10 |
| 1t88c | 96 | 1t | 第四代至强可扩展 | - | 336 | 20 |
| 73x | 128 | 512g | 第三代EPYC | - | 336 | 2 |
| 52 | 48 | 512g | 第二代EPYC | - | 336 | 1 |
| 63 | 128 | 512g | 第三代EPYC | - | 336 | 1 |
| v3-6t | 144 | 6t | 至强E7 v3 | - | 336 | 7 |
| v3-64 | 24 | 64g | 至强E5 v3 | - | 1440 | 225 |
| v3-128 | 24 | 128g | 至强E5 v3 | - | 336 | 6 |
| spec-gpu | - | - | - | - | 无限制 | - |
| 2a100-40 | 40 | 192g | 第二代至强可扩展 | 2*a100 40g | 336 | 1 |
| 4a100-40 | 56 | 384g | 第二代至强可扩展 | 4*a100 40g | 336 | 3 |
| 2a100-80 | 40 | 192g | 第二代至强可扩展 | 2*a100 80g | 336 | 1 |
| 4a100-80 | 128/32 | 512g | 第三代/二代EPYC | 4*a100 80g | 336 | 4 |
| hgx | 128 | 1t | 第三代EPYC | 8*a100 80g | 336 | 2 |
| 4v100-16-e5 | 24 | 64g/128g | 至强E5 v3 | 4*v100 16g | 336 | 2 |
| 4v100-16-sc | 40 | 192g | 第一代至强可扩展 | 4*v100 16g | 336 | 1 |
| 2v100-32-e5 | 24 | 256g | 至强E5 v3 | 2*v100 32g | 336 | 1 |
| 2v100-32-sc | 40 | 192g | 第二代至强可扩展 | 2*v100 32g | 336 | 1 |