CloverLeaf 编译优化挑战
作者:Charley-xiao
序幕
漆黑宇宙的尽头,有一条几乎被遗忘的旋臂。那里星光稀薄,像是天幕上被擦去的一笔。就在这片幽暗之中,值夜的观测员艾诺听见了警报——那是一种无法忽视的低沉的嗡鸣,仿佛有人在全宇宙生物的心底敲响巨鼓。 他抬头望向主屏,只见一幅灰阶星图中央亮起不祥的方形波纹:
方格海,苏醒了。

DANGER
旋臂到达临界状态,预计三十分钟后撕裂!
雪崖哨站的百米合金穹顶被强行开启,冷白探照灯刺穿真空,照向远处那片"海洋"。方格海原本安静得像一张铺在星空的暗色丝毯,此刻却闪烁出交错的蓝紫脉冲,一圈圈能量波浪向外翻卷,速度每分钟翻一倍。 "按照现在的增幅,二十九分钟后,外旋臂的引力平衡会先瓦解,然后整条臂被撕碎。"首席动力学家柯帕在通讯频道里说。她的声音没有颤抖,但说完那串数字后,舱室陷入短暂的寂静。
应急频道闪烁成一片红海。来自千座文明的代表以全息投影出现在同一张圆桌旁:碳基、硅基,还有被人类称作"流光"的能量体。没有寒暄,没有礼节。 "唯一的解决办法是模拟湍流," 柯帕点开一份简报,网格上的涡旋图案像怒吼的巨兽,"可这里不是普通流体,而是二维量子晶格。天枢必须在三十分钟内跑完四个算例,否则——" 她没把结局说出口。所有人都知道那意味着什么。
天枢并非一颗行星,而是一座漂浮在零维奇点上的环形超算。十万台计算塔像灯塔般环抱中央空洞,每台塔身上万条光纤汇成瀑布,顺着金属嵴脊奔腾。启动指令下达的瞬间,整座星门亮起比恒星还刺目的白光,照得工程甲板犹如白昼。 然而,当输入参数后,调度核心只给出一个答案:
INFO
执行任务所需引擎:CloverLeaf(公元 21 世纪,人类代码)。
那段陈旧程序被尘封在档案最深处,格式各异、注释混乱。它之所以被选择,只因为它用交错网格存储能量与密度,这恰好对应方格海的物理纹理。
编译室位于天枢最深的主机腹地,空气干燥得仿佛随时会碎裂。圆柱形冷却管壁上覆着薄冰,霜气缭绕。工程师、量子算法师、流光译码体并肩而立,眼睛盯着同一块 360° 环幕。 屏幕上,古老的 Fortran、C++、OpenMP 指令被高亮标红——兼容性报错如雨。柯帕深吸一口气:"从现在开始,我们只有一种敌人:时间。"
DANGER
旋臂预计十五分钟后撕裂!
键盘敲击声如暴雨。每一次回车,编译器便吐出新的错误:寄存器别名冲突、缓存行伪共享、未知指令集……错误清单像藤蔓疯长,又被一行行修补砍断。汗水沿着护额滴进面颊的照明灯,闪出细小电弧。
"载入算例一——湍流撕裂。"
执行文件启动,数据洪流瞬间灌满主节点。曲线在坐标系里颤抖,像被掐住喉咙的蛇。十秒后,屏幕突然熄灭。
INFO
SYSTEM SHUTDOWN
缓存溢出,溃败。
没人咒骂,也没人退缩。旧错误被标记,替换方案在神经光束里飞速生成。有人接管向量寄存器,有人调低内存对齐阈值,还有人拆掉整段重复计算的内核。
再运行。
这一次,曲线稳住了第一道波峰,却在第二道湍流处崩断。就在计数到 95 % 时,舰桥灯火猛地失压。
DANGER
Terminated with exit code 137
那一瞬,系统骤然撕成乱码;启明号主引擎刚点火便被异常反向推力贯穿,方格海的指数裂缝在星窗外炸开。半个宇宙被卷进 137 号错误,栈回溯化作炽白潮汐,连光都失去指向。在艾诺即将随洪流抹消之际,编译器将他连同残骸压缩成一束单行注释,回溯到最后一次干净提交:几千年前、方格海尚在胎息的年代。
第一幕:竞赛概览
本幕更改日志
2025/6/30:修复了错误的评分计算方式,更改四样例为两样例。
简介
CloverLeaf 是一个迷你应用程序,它模拟大型流体力学运算中的显式二阶精确方法求解 2D 笛卡尔网格上可压缩欧拉方程的过程。它采用交错网格存储数据,每个单元存储三个值:能量、密度和压力,速度矢量存储在每个单元角。CloverLeaf 由沃里克大学,布里斯托大学,及及一些其他机构的研究者共同开发,是用于检测超级计算系统扩展性瓶颈和性能可移植性的代表性程序之一。
方程组与数值求解
CloverLeaf 网格采用二维笛卡尔坐标(即将来会扩展到三维)。 在每个单元中心存储 能量、密度、压力 三个标量,而 速度向量 则存储在单元顶点处——这种“部分变量在单元中心、部分在顶点”的布局称为 交错网格(staggered grid)。
可压缩欧拉方程是一组三个偏微分方程,分别描述能量、质量和动量守恒。CloverLeaf 采用 显式有限体积 方法给出 二阶精度 解,具体流程如下:
- 拉格朗日步骤: 使用预测—校正(predictor–corrector)方案,根据计算出的时间步长 Δt 推进解;此时网格节点随流体速度“漂移”。
- 对流重映射(remap): 为将网格形状恢复到初始位置,采用二阶 Van Leer 算法,对能量、质量、动量在 x / y 两个方向各做一次对流扫描。每一步交替改变扫描先后次序,以保持二阶精度。 在重映射时,需要根据流向使用“迎风”侧(upwind)数据。虽然网格几何并未真正变形,但通过计算单元面的平均速度来近似各面通量。
欧拉方程属于双曲型方程,解中会出现激波等不连续性,简单的二阶近似会在激波处失效并产生“振铃”现象。为抑制振铃,CloverLeaf 引入 人工黏性压力:一旦检测到激波,使局部精度降为一阶,从而保持解的单调性。
时间步长由 最大声速 决定——Δt 不能超过最快声波穿过单元所需时间,再乘以安全系数以确保稳定。此外还做两项检查:防止顶点互相“追尾”,以及避免单元体积变为负值。
为了闭合方程组,需要 状态方程(EOS)。CloverLeaf 采用理想气体 EOS,γ=1.4。目前程序仅支持“单材料”情形,即域内所有状态共享同一物质——未来版本会加入多材料支持。
算法实现
如果只考虑串行架构,算法实现十分直接。但面向现代/未来硬件,CloverLeaf 的设计强调以下方面:
- 内存访问与局部性
- 编译器优化友好
- 线程并行 & 向量化
计算被拆分为大量 内核(kernel),每个内核只做一件事:按固定模板遍历全网格并更新一组变量。内核内部控制逻辑极少,方便编译器优化。 为避免写依赖、提高并行度,必要时会把更新结果写入网格副本。这样每个单元都能独立更新,天然适合线程化和 SIMD 向量化。
边界单元与 Halo 交换
计算域外围通过 边界条件 关闭方程。网格周围再包一圈或两圈 Halo 单元,为计算模板提供邻域数据,内核本身无需更新这些单元。Halo 数据来源有二:
- 处理器分区内部:直接把相邻分区的真实单元值复制过来;
- 物理边界:应用物理边界条件(目前仅实现“反射”边界)。
竞赛目标
本次竞赛的目标是对 CloverLeaf 进行编译优化,提升其性能。我们将提供一个 CloverLeaf 的简化版本,包含了两个算例,每个算例都包含了不同的物理模型和参数设置。你需要在给定的时间内完成所有算例的编译优化,并提交你的代码和结果。选手需要使用 GNU 以及 Intel 编译器进行编译优化,而 AOCC、HPC-X 等其他编译器为附加 bonus。
参赛队伍需要在 2 台计算节点上完成制定算力的评测,用于计分的指标是问题求解时间,即程序输出的 clover.out 最后 1 个 Wall clock.
规则
代码编写规则
- 总体要求:不得修改计时代码,以及计时代码与其他函数的相对位置。
- 编程语言:仅限 C、C++ 或 Fortran(版本 ≥ C11、C++11、Fortran 2008)。
- 算法要求:禁止改变 CloverLeaf 的物理模型与数值格式;可在保证数值守恒的前提下进行重排、循环分块、SIMD 化等纯 CPU 优化。
- 输入/输出:不得改动
*.in、*.out文件及其格式,输出需与参考结果一致。 - Bonus CPU 实现:
- 允许在
CloverLeaf_ref之外,自行移植或重写 CPU 版本(如 CloverLeaf_OpenMP、OPS/Polyhedral、SYCL/Kokkos 等),编译后仍应生成单一可执行文件。 - 不得编译或调用任何 GPU 专用后端(CUDA、HIP、OpenACC
device_type=gpu、oneAPI Level Zero 等);若检测到 GPU 相关符号,视为违规。 - 允许依赖集群现有的软件栈;如需额外依赖,请在报告中给出 Spack/Make/CMake 步骤。
- 允许在
测试规则
- 运行环境:竞赛指定 CPU 集群(无 GPU)。规模 ≤ 2 计算节点;不设核心上限;整机运行时间 ≤ 30 分钟。
- 测试用例:共 2 组,位于
cases/,任何实现都必须使用同一份clover.in。
正确性验证
- 以参考输出
clover.out为基准:- Volume、Mass 在计算过程中保持守恒;
- 最终 Kinetic Energy 与参考值偏差 ≤ ±0.5 %。
- 组委会将审阅代码/文档,确认仅做 CPU 优化而未改变物理过程。
- 必要时可要求参赛队在不同线程数或编译器参数下复测。任何算例若未通过正确性验证,其性能得分计 0。
性能评分
设
:参考实现 ( CloverLeaf_ref) 用编译器在算例 上的耗时; :选手提交(可为 ref 或 Bonus CPU 实现)用编译器 在算例 上的耗时。
每个 (实现,编译器,算例) 的得分为
其中权重
| 代码实现 | 编译器 | |
|---|---|---|
| CloverLeaf_ref | GNU / Intel | 10 |
| CloverLeaf_ref | 其他编译器(AOCC、Clang 等) | 4 |
| Bonus CPU 实现 | 任何合规编译器(但仅限一个) | 2 |
非常重要!
只允许提交一份 Bonus CPU 实现而且只计算一个编译器的分数,且必须在 CloverLeaf_ref 之外。若提交了多个 Bonus CPU 实现或者一个 Bonus CPU 实现但是多个编译器版本,则根据抓瞎法随机挑选一个实现的性能分。
总性能分 为 ref 版本各编译器两个算例所得
工程分数
- 工程报告(PDF):
- CloverLeaf 算法流程与代码结构说明
- 性能分析、优化与实现过程
- 测试结果与分析
- 复现方法说明
- 代码可移植性:须能在其他服务器编译与验证。
- 创新性
- 直接抄袭公开资料 → 0 分
- 借鉴学术/工业方法并改进 → 1–2 分
- 提出原创优化方法 → 3–4 分
- 可复现性
- 无法复现 → 0 分
- 可复现提交测试结果 → 1–3 分
- 步骤清晰、依赖说明完整 → 2–3 分
- 表达质量
- 文字混乱/抄袭 → 0 分
- 语言通顺、论述清晰 → 1–2 分
- 语言精练、资料来源准确、图文并茂 → 3 分
交付须知
注意
赛中提交格式请见附录四。
所有提交都需要遵循以下格式。
CloverLeaf_SCC/以及各个编译器的运行脚本job.<compiler>.slurm
完整源代码以及作业脚本,供组委会运行验证;附加说明请写在根目录 README。CloverLeaf_SCC/results/<compiler>/case<1-2>/*(赛中可不包含)
每算例需包含:clover.out- 作业脚本
- 作业调度系统输出
- 使用 sbatch:需提供
clover.out- 1 个 shell 脚本
- 标准输出
<JobID>.out - 错误输出
<JobID>.err
文件名中必须含 Slurm Job ID。
CloverLeaf_SCC/results/report.pdf(赛中可不包含)
工程报告(可为 docx 或 pdf)。
第二幕:崩落的界域
剧烈的失重感消散后,艾诺扑通一声落进松软草地。鼻尖传来潮润花香,耳旁是青蛙与虫鸣——这些声音在真空中根本不可能存在。他挣扎着坐起,只见月光下水面微漾,倒映着一块巨石,石上鎏金四字:"南方科技大学"。
他置身地球上南科大校园中央的湖畔。腕表在黑暗里闪烁日期:公元 2025-09-01。
几千年的时差,让他几乎忘了呼吸。
夜色宁静,教学楼旁的路灯投下暖黄光晕。湖对岸,一丹图书馆玻璃幕墙映出星点反射;远处学生宿舍高耸,大部分宿舍的灯尚未熄灭。 艾诺跌跌撞撞穿过步道,路过自动贩卖机时才恍然——这里的电子支付还要刷校园卡,量子指纹识别要再等几个世纪。 但他无暇感慨。唯有一件事在脑中回荡:方格海必须被重新封印,而钥匙依旧是 CloverLeaf。
凌晨两点,理学院大门敞开,灯火通明。一群学生围着陈旧的木桌调试代码,桌面堆满方便面杯。最外侧坐着一位短发女生,聚精会神盯着屏幕。IDE 中赫然是 CloverLeaf。
"对不起,打扰一下。"艾诺低声开口,却仍惊起一片侧目。
女生摘下耳机:"你也在跑这玩意儿?我叫 hachimi,大四超算竞赛队。"
他们把代码拉到校级超算 "启明 2.0" 上。
第一次编译
OpenMP 版本不匹配
第二次编译
节点掉线
凌晨四点,机房里只剩风扇轰鸣与键盘噼啪。hachimi 揉着通红的眼角:"再这样下去,明早比赛都要弃权了。"艾诺心底却在打鼓:未来的大崩落已经提前显形——方格海在他来到 2025 的同一刻,便开始提前躁动。
南科大超算俱乐部交流群(QQ 群号:897073438)像被丢进了炸药:
【曼波】在 04:14:11 说道:
@所有人 有人来帮忙跑下 CloverLeaf 吗?hachimi 有点撑不住了,明天 ddl。/kel/kel/kel
【路人甲】在 04:15:28 说道:
有夜宵吃吗,有就去
【hachimi】在 04:16:33 说道:
来就有,理学院一楼速速
【misaka114514】在 04:19:11 说道:
来咯
不到半小时,理学院一楼人满为患。每一次 make 通过,就在门口铜钟上敲一下。钟声回荡在安静的校园,惊醒巡逻的保安,也把更多夜猫子吸引进来。
夜色欲尽,天空泛起鱼肚白。艾诺站在图书馆露台,眺望深圳湾方向的云层。那里,本该宁静的高空等离子层闪过诡异电弧——二维量子网格正在那里成形。 他掏出残存的未来量子通信片,折射的全息数据显示:
WARNING
方格海初始裂速:0.03 c,预计 72 小时后进入指数阶段。
时间,比他在 4275 年记录的提前了整整三天。
黎明的钟声划破寂静,喷泉准点点亮。理学院内,最后一次编译结束,屏幕打出绿字:
IMPORTANT
This test is considered PASSED
Wall clock: 17.342 s
铜钟被全场齐拉,声浪滚过湖面,与喷泉水柱交织在晨雾中。 然而艾诺清楚,真正的战场并非校赛,而在那片尚未完全显形的方格海。
【艾诺】在 06:48:17 写道:
我们要把这段代码,加固到任何时代、任何硬件都能运行。
"从南科大开始,让时间线改写。"他心想。
湖面晨曦渐亮,映出校园与未来交叠的倒影。崩落的界域已然逼近,而新的抵抗也自此启程。
幕间:快速上手
本幕更改日志
2025/7/2:更改了作业脚本 job.slurm,使其不继承环境变量,同时增加了对部分参数的说明。
编译
首先,登录在超算平台的账号,下载压缩包,使用命令 tar -xzvf CloverLeaf20250622.tar.gz 解压后进入根目录。
然后,使用 module load ... 指令来用指定的编译器来编译 CloverLeaf。你可以使用 module avail 来查看平台上可用的编译器及相关库。当然,你也可以选择自己安装喜欢的编译器版本(我们强烈鼓励这种做法!)
最后,可以选择修改 Makefile 中的各个选项,并使用 make COMPILER=... 来进行编译。编译成功后,会看到当前目录下有名为 clover_leaf 的可执行文件。
运行
在 CloverLeaf_SCC/ 目录下,新建作业脚本 job.slurm,用指令 sbatch job.slurm 来提交作业。示例作业脚本如下:
job.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48 # 可以更改
#SBATCH --ntasks-per-node=24 # 可以更改
#SBATCH --cpus-per-task=2 # 可以更改
#SBATCH --export=NONE
#SBATCH --exclusive
# 注意:比赛环境为 2 节点,每节点 48 核
# 这意味着,cpus-per-task 乘以 ntasks-per-node 小于或等于 48 就可以了
# 这里有丰富的调参空间,欢迎尝试
lscpu
source ~/.bashrc
source /work/share/intel/oneapi-2023.1.0/setvars.sh # 可以更改,但是需要和编译的时候使用的一致
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" clover.in
# Use Slurm-native launcher; mpirun also works if preferred
# srun --mpi=pmix -n "$NP" ./clover_leaf
mpirun -n "$NP" ./clover_leaf
mv clover.out "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fijob.lsf (legacy)
#!/bin/bash
#BSUB -q ssc-cpu
#BSUB -W 02:00
#BSUB -J cloverleaf
#BSUB -o %J.out
#BSUB -e %J.err
#BSUB -n 32
#BSUB -R "span[ptile=16]"
set -euo pipefail
lscpu
module purge
module load openmpi/4.1.1_oneapi # 改为你想用的 module
export OMP_NUM_THREADS=2 # 可更改
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${LSB_DJOB_NUMPROC:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
PASS_CNT=0
FAIL_CNT=0
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..4}"
for i in $(eval echo $CASES); do
printf "▶ Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" clover.in
mpirun -np "$NP" ./clover_leaf
mv clover.out "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.001)}'; then
printf " ✅ Passed (ref=%s, out=%s, eps=%s%%)\n\n" "$ref_ke" "$my_ke" "$rel_pct"
((PASS_CNT++))
else
printf " ❌ Failed (ref=%s, out=%s, eps=%s%%)\n\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
if (( FAIL_CNT == 0 )); then
printf "🎉 All cases passed within 0.1%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fi攻克路径推荐
复现 Baseline
确认 CloverLeaf 在默认编译选项下全部通过校验脚本。
编译选项调参
下面列举一些常用的编译器调参套路,供参考。详细教程见各编译器文档。
| 步骤 | 目标 | 技巧 / 参考 |
|---|---|---|
| 热点剖析 | 找到热点函数 | perf record, gprof, -qopt-report (Intel) |
| 编译选项扫描 | 快速找到合适编译选项 | gcc -O3 -march=native -flto, 再叠加 -funroll-loops, -fprefetch-loop-arrays;或 icx -ipo -Ofast -xHost |
| 向量宽度 | 利用 AVX‑512 / Zen4 ISA | -qopt-zmm-usage=high (Intel);-mprefer-vector-width=256 (AOCC) |
| LTO / ThinLTO | 跨模块内联、去冗余 | -flto=thin (Clang 18) |
| PGO | 基于 Profiling 调优 | -fprofile-generate/use (GCC);-prof-gen/use (Intel) |
| ... | ... | ... |
第三幕:聚合的塔尖
黎明过去不过六个小时,南科大超算中心便被临时改造成一座"灯塔"。 启明 2.0 机柜上方的检修平台被拆下护栏,超算队队员们把一块块 LED 调试灯接入总控,总功率足以让整面玻璃幕墙泛出幽蓝光晕。
艾诺站在机房走道尽头,望着这些分布式"萤火"汇成的光柱,恍惚间看见未来天枢环塔的倒影。 "塔尖只差最后一块基石,"他低声说,"一块能在任何时代自适应膨胀的编译器。"
午后,hachimi 在 GitHub 私信里收到一份匿名 PR:
Pull Request
Add: temporal-portable backend (TPB) for CloverLeaf
补丁注释出奇简短,却精准修复了先前最棘手的 内存对齐与向量冲突。
更诡异的是,它附带一段时间戳:4275-09-21T17:03Z。
hachimi 告诉了艾诺,艾诺立马就明白了,那是来自天枢末日前最后一次成功编译的残影。
"你也许不理解,但是这是未来自己给我们的回信。" 艾诺说。
"要不要用?"hachimi 问道。
艾诺沉默片刻,点头:"用。但要先看懂,再接进主干,不能让它变成黑匣子。"
傍晚六点,校园进入用电高峰,供电处发来警告:
WARNING
检测到超额功率请求,请尽快降载。
但塘朗山脚下,铜钟已敲到第九下——最后一次 make 开始链接。 所有人屏息。风扇像合唱团排山倒海,LED 灯泡则一颗颗熄灭——电流被抽走,投入最终编译。
1 % … 20 % … 63 % … 99 % 进度条在 100 % 停顿半秒,终端打印绿字:
IMPORTANT
>> TPB enabled: arch=GENERIC, vec=256-bit
>> Linking complete.
随即,整座启明塔灯火熄灭,瞬息又全部亮起,像夜航的灯塔刺破暮色。
hachimi 立即启动"四大算例"并开启 直播。信号从塘朗山天线跃向高空——
- case 1:湍流撕裂 → 收敛
- case 2:质量回喷 → 收敛
- case 3:共振自稳 → 收敛
- case 4:临界熵泄漏 → 进度 87 % … 88 % …
就在所有人以为结局会与凌晨那次失败如出一辙时,深圳湾方向突然亮起一道银线。 那是尚未完全显形的方格海,它的边缘被算例数据牵引,折叠成一道垂直光帘,直指天际。
DANGER
方格海裂速抑制失败! 外场指数项再次上升。
"是电力的问题,"艾诺惊呼,"快,把能用上的全部用上!"
机械系和物理系合力调整风冷机架,超频至额定 110 %;其他人递上备用电力变压器,把南科大所有学院的电力投入供电。
在水汽蒸腾的夜空下,塘朗山、启明塔与深圳湾光帘形成三角。

零点零分零秒,全校熄灯。所有剩余电力汇聚到那条 MPI 环路——一根"看不见的电缆"绕过行政楼、宿舍、松禾运动场,最后返回启明塔。
CloverLeaf 第三轮启动,实时输出被投射到主楼外墙:
INFO
Wall clock (global): 12.874 s
STATUS: CONVERGED
与此同时,深圳湾的光帘骤然暗淡,折回一圈圈残光,像潮水退入海床。 南科大上空,仅余一簇尾焰般的极光,安静漂移,直至无声消散。
风停,灯复燃。校园里爆发山呼海啸的欢呼,足以把阅湖水面震出涟漪。
hachimi 抱着笔记本冲上顶层露台:"Wall clock 12.874 秒!比 baseline 快了近 40 %!"
艾诺却把目光投向更远处——他知道,这只是第一阶段。方格海被推迟,但并未根除;宇宙另一端,真正的天枢仍在倒计时。
"塔尖已聚合," 他在群里敲下最后一行字, "下一步——连塔成环。"
灯火掩映的夜空下,南科大的剪影像一枚安静的符号,镌刻在时间线的中缝。 远处海面,微光起伏,无声预告着下一场波澜。
第四幕:回首的天际
暴风般的呼喊与鼓掌声散去,校园上空只剩细雨。水珠沿启明塔塔尖淌下,折射出淡淡虹光。
艾诺静静伫立于塔顶防雷桅杆旁,任雨丝落在肩头。远处深圳湾已褪去银幕,只留下城市灯火与海雾交融的朦胧轮廓——仿佛什么都不曾发生,又好像一切都被重写。
hachimi 端着两杯冒着热气的豆浆走来,递给他:"你该歇一歇了。"
艾诺接过,仰头喝了一口。暖流滑过喉咙,他才意识到自己连续醒着三十七个小时。雨声、心跳、服务器机架尚未彻底平息的风扇轰鸣,此刻交织成一种近乎安宁的节奏。
凌晨 03:12,南科大超算中心管理员在后台日志里发现一条异常留言:
留言板
标题:Round #0 complete
正文:
感谢你们替我们点亮第一座塔。
当你们读到这行字,量子裂隙已锁相,
但真正的环路共有十二座灯塔——
七座在人类文明疆域,
五座远在深空,以光年的尺度彼此守望。
下一段坐标:-12° 15′ 58″, +130° 18′ 40″
请把火炬传下去。
祝好,
Chronos
管理员一度以为是学生的愚人彩蛋,直到日志显示该留言在 0.74 毫秒内写入又自我抹除,连残影也不剩。
当天午后,南科大小剧场举行了原本属于校赛的颁奖仪式。屏幕上滚动播放着比赛排名,却没人真正把心思放在那里。hachimi 在台上简单致辞后,把奖杯递给艾诺:"真正的队长,应该是你。" 艾诺却把奖杯转交给在场所有参赛者:"如果没有每一个人,这座塔就不会亮。"
仪式结束,人群散去。 启明塔一层机房里,淡蓝光线依旧闪烁,一如初始。艾诺整理了 README,将仓库设为公开。commit 信息只有一句:
IMPORTANT
pass the torch, to wherever light is needed next
夜幕再次降临,雨已停。艾诺与 hachimi 沿着湖畔下行。湖面如镜,映着塔尖灯火与遥远星群。
"坐标指向太平洋正中央。"hachimi 抬头看星空,"那里连一块礁石都没有。"
"塔未必非要建在陆地。"艾诺笑了笑,"或许是漂浮阵列,或许是海底主机,也可能是另一所学校的灯塔——谁知道呢?"
他们相视而笑,不再多言。脚步声在雨后石阶上回荡,像是另一支无形编译器,正在把新一段时代代码缓缓链接。
终幕
在深圳湾光帘熄灭后的第三天清晨,艾诺再次启动了腕上的量子回溯计。
倒计时的指针依旧停在 00 : 30 : 00——与他刚被抛出天枢时一模一样,没有向前,也没有向后。
hachimi 把这枚冰冷的金属圆盘翻来覆去:"所以……你的 '回家' 条件还没满足?"
艾诺点点头,将计时器合上:"Chronos 的留言说的是十二座灯塔。南科大只是第一座。要让时空闭环,把方格海彻底钝化,我得和你们一起,把剩下十一座也点亮。"
"那点亮之后呢?"
"倒计时才会继续流动,直到归零的那一刻——我就会被送回 4275 年,去接回真正的终局。"
两人相顾无言。学生宿舍区的晨雾弥散,湖面轻轻荡开一道圆弧,好像在为未来铺路。
hachimi深吸一口气,伸出手:"那就别耽搁了,下一站——太平洋坐标 -12°15′58″、+130°18′40″。"
艾诺握住她的手,笑意里有微不可察的释然:"等环路闭合,我在 4275 年的天枢,为你们守最后一班岗。"
于是,关于艾诺是否"回得去"的答案,也被写进了那十二座灯塔的行程表——
回去,意味着他们成功拯救了未来;
留在这里,则说明未来已不需要再被拯救。
无论哪一种,都值得他奔赴。
说明与致谢
本赛题为南方科技大学 2025 年超算比赛基础赛道编译优化赛题。本赛题所有资源遵循 CC BY-NC-SA 4.0 协议,允许非商业性使用与修改。。如有任何问题,请提出 issue 或联系 12211634@mail.sustech.edu.cn. 出题人:Charley-xiao.
故障排除
从源码安装 OpenMPI 时,./configure 报错 working directory cannot be determined
该故障源于集群文件系统问题,目前已修复。未修复时,可以手动将所有 configure 脚本中的 working directory 相关行注释掉。一个可以成功 ./configure 的版本发布在这个路径下 /work/share/software/openmpi-5.0.8.tar.bz2,可以使用 cp 指令进行复制,并使用指令 tar -xvjf openmpi-5.0.8.tar.bz2 进行解压。
附录一:基准时间参考
基准设置:2 节点,每节点 24 tasks,每 task 2 threads.
注意
基准时间可能会更新。
基准时间:
| 算例 | GNU | Intel | AOCC | HPC-X* | MVAPICH | MPICH | NVHPC |
|---|---|---|---|---|---|---|---|
| 1 | 1033.1695 s | 519.8045 s | 1111.9942 s | 811.9700 s | 519.0863 s | 409.9613 s | 818.3194 s |
| 2 | 17.6088 s | 8.0040 s | 30.2586 s | 13.7310 s | 8.2421 s | 7.2842 s | 20.5116 s |
*:使用 NVIDIA HPC SDK 自带的 HPC-X 不算在 HPC-X 一栏中,而算在 NVHPC 一栏中。HPC-X 这一栏指的是独立发布、可单独下载的版本。
???
你发现了一只野生的 oiia 哈基米!

| 算例 | Intel |
|---|---|
| 1 | 372.6201 s |
| 2 | 5.0754 s |
诶,为什么集群会突然变得这么快呢?不会是哈基米你在捣乱吧!
算了,不想改表格了(累趴)。
【哈基米】:Oiiai, oiiai Oiiai, oiiai Oiiai, oiiai Oiiai, oiiai. Oiiai, oiiai Oiiai, oiiai Oiiai, oiiai, oiiai...
附录二:安装并使用 AOCC 编译器
警告
AOCC 的安装需要基于 GCC 12 或更高版本的编译器。请先按照附录三“使用 GNU 编译器”安装 GCC 15.1。
AOCC 编译器是 AMD 官方的编译器,支持最新的 Zen5 架构。在本次比赛中,由于集群全部为 Intel 节点而不是 AMD,AOCC 编译器的表现可能不如预期,所以作为 bonus,可选做,其基准分数为 4 分(而不是 10 分)。如果你想使用 AOCC 编译器,可以按照以下步骤安装。
- 进入 AMD AOCC 官网,下载最新版本的 AOCC 编译器。
- 解压下载的压缩包,并进入解压后的目录。
tar -xvf aocc-compiler-5.0.0.tar
cd aocc-compiler-5.0.0
./install.sh- 这会生成一个
setenv_AOCC.sh脚本,用于设置 AOCC 编译器的环境变量。 - 运行下面的命令以加载环境变量,然后就可以使用 AOCC 编译器进行编译了。
source setenv_AOCC.sh- 下载 OpenMPI 5.0.8 并解压进入目录。
wget https://download.open-mpi.org/release/open-mpi/v5.0/openmpi-5.0.8.tar.gz
tar -xvzf openmpi-5.0.8.tar.gz
cd openmpi-5.0.8- 启用 AOCC 编译器。
export GCC15=<安装GCC>=12的位置>/gcc/15.1
export CC="clang --gcc-toolchain=$GCC15"
export CXX="clang++ --gcc-toolchain=$GCC15"
export FC="flang --gcc-toolchain=$GCC15"
export LD_LIBRARY_PATH=$GCC15/lib64:$LD_LIBRARY_PATH
./configure --with-slurm --prefix=<你想安装到的目录>/openmpi-aocc
make -j$(nproc) && make install
export PATH=<你安装到的目录>/openmpi-aocc/bin:$PATH
export LD_LIBRARY_PATH=<你安装到的目录>/openmpi-aocc/lib:$LD_LIBRARY_PATH
which mpicc在使用时,执行:
export PATH=<你安装到的目录>/openmpi-aocc/bin:$PATH
export LD_LIBRARY_PATH=<你安装到的目录>/openmpi-aocc/lib:$LD_LIBRARY_PATH进入 CloverLeaf_SCC/ 目录,使用 AOCC 编译器编译 CloverLeaf:
make COMPILER=AOCC然后提交任务:
job.aocc.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48 # 可以更改
#SBATCH --ntasks-per-node=24 # 可以更改
#SBATCH --cpus-per-task=2 # 可以更改
#SBATCH --exclusive
# 注意:这里不能不继承环境变量,否则 slurmstepd 调不到 prted
# 注意:比赛环境为 2 节点,每节点 48 核
# 这意味着,cpus-per-task 乘以 ntasks-per-node 小于或等于 48 就可以了
# 这里有丰富的调参空间,欢迎尝试
lscpu
source ~/.bashrc
source <你安装AOCC的位置>/setenv_AOCC.sh
export PATH=<你安装OpenMPI的位置>/openmpi-aocc/bin:$PATH
export LD_LIBRARY_PATH=<你安装OpenMPI的位置>/openmpi-aocc/lib:$LD_LIBRARY_PATH
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" clover.in
# Use Slurm-native launcher; mpirun also works if preferred
# srun --mpi=pmix -n "$NP" ./clover_leaf
mpirun -n "$NP" ./clover_leaf
mv clover.out "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fi附录三:保姆级教程
使用 Intel oneAPI
Intel oneAPI 已经在集群上装好,使用以下指令来加载环境变量:
source /work/share/intel/oneapi-2023.1.0/setvars.sh此时运行
which mpicc应得到
/work/share/intel/oneapi-2023.1.0/mpi/2021.9.0/bin/mpicc说明 Intel MPI 的可执行文件已经排在 PATH 前列。
接着进入 CloverLeaf_SCC/ 并编译:
make COMPILER=INTEL MPI_COMPILER=mpiifort C_MPI_COMPILER=mpiicc然后提交任务:
sbatch job.slurm注意:该集群目前提供的 oneAPI 版本较旧(2023.1,对应 Intel MPI 2021.9),因此只包含经典封装器 mpiicc/mpiicpc/mpiifort,还不支持 mpiicx/mpiicpx/mpiifx。mpiicc 与 mpiicx 的区别如下:
| 封装器 | 默认后端 | 是否继续维护 |
|---|---|---|
mpiicc | icc(经典 Intel C 编译器) | 仍在,但被标记为 classic |
mpiicx | icx(LLVM-based Intel C 编译器) | 主推 |
mpiicc 识别所有 classic ICC 特有参数;-xCORE-AVX512 等写法对 mpiicx 不一定成立。mpiicx 支持标准 LLVM/Clang 选项,如 -march=native、-flto=full,并能与 -fsanitize、-fprofile-generate/use 等现代工具链联动。
Intel 已宣布 classic 编译器将在 oneAPI 2027(暂定)后停止更新安全补丁;届时只剩 icx/ifx。因此官方推荐新项目直接用 mpiicx/mpiifx,老项目逐步迁移。
对大多数 HPC 内核,两者生成的代码性能非常接近;不过 icx 在自动向量化与 OpenMP 5.x 支持上更活跃。若需使用最新 -qnextgen 自动并行特性或改进版 OpenMP Offload,务必切到 mpiicx。
目前,组委会正在安装更新版本的 oneAPI 以确保大家能用上最新的 mpiicx/mpiifx。如果不想等待,你也可以自行安装最新版本。届时,编译 CloverLeaf 的指令将变为:
make COMPILER=INTEL MPI_COMPILER=mpiifx C_MPI_COMPILER=mpiicx基准时间也将相应发生改变,敬请关注。
提交任务后,会显示 Submitted batch job <xxx>,其中 <xxx> 是任务 ID。你可以使用 squeue 查看任务状态,或使用 sacct -j <xxx> 查看任务详情。
通过 cat <xxx>.out,你可以查看任务输出结果。若任务成功完成,输出文件中会显示类似以下内容:
=== Correctness Check ===
Num proc: 48
? Case 1 : Simulating...
Clover Version 1.300
MPI Version
OpenMP Version
Task Count 48
Thread Count: 2
Output file clover.out opened. All output will go there.
✔ Passed (ref=8.0560000000e-02, out=8.0560000000e-02, eps=0.0000%)
⏱ Wall clock = 375.285696983337s
? Case 2 : Simulating...
Clover Version 1.300
MPI Version
OpenMP Version
Task Count 48
Thread Count: 2
Output file clover.out opened. All output will go there.
✔ Passed (ref=3.0750000000e-01, out=3.0750000000e-01, eps=0.0000%)
⏱ Wall clock = 5.81983780860901s
=== Summary ===
Passed: 2, Failed: 0
Wall clock per case:
Case 1 : 375.285696983337 s
Case 2 : 5.81983780860901 s
✅ All cases passed within 0.5% tolerance.如果最后显示 All cases passed within 0.5% tolerance.,则表示你的代码通过了所有测试用例。那么恭喜你,接下来的任务就是做性能分析以及优化了!祝你好运!
使用 GNU 编译器
重要更新
安装 GCC 15.1 的时候需要带上一些优化选项,否则性能会差一些。
注意
不一定非要从源码构建 GCC,也可以下载预编译的二进制包,实测会快一些。
这里给出一种自己编译安装的通用做法,既不会用到系统自带 GCC 8.5,也能确保 OpenMPI 5.0.8 完全用 GCC 15.1 编译。
- 编译并安装 GCC 15.1
wget https://ftp.gnu.org/gnu/gcc/gcc-15.1.0/gcc-15.1.0.tar.xz
tar -xf gcc-15.1.0.tar.xz
mkdir gcc-15.1.0/build && cd gcc-15.1.0/build
../contrib/download_prerequisites
../configure \
--prefix=<你想安装到的位置>/gcc/15.1 \
--enable-bootstrap \
--enable-languages=c,c++,fortran,lto \
--disable-multilib \
--with-arch=native --with-tune=native \
--with-system-zlib \
--enable-shared --enable-threads=posix \
--enable-checking=release \
--enable-__cxa_atexit \
--disable-libunwind-exceptions \
--enable-gnu-unique-object \
--enable-linker-build-id \
--with-gcc-major-version-only \
--with-linker-hash-style=gnu \
--enable-plugin \
--enable-initfini-array \
--with-isl \
--disable-libmpx \
--enable-gnu-indirect-function \
--enable-cet \
--with-pkgversion="GCC 15.1 (SUSTCSC Customized)" \
--with-bugurl="mailto:12211634@mail.sustech.edu.cn" \
--build=x86_64-redhat-linux
# 上面这些选项可以通过 gcc -v 来查看,主要是为了模仿发行版 configure 的设置以获得最佳性能
make -j$(nproc)
make install- 激活 GCC 15.1
export PATH=<你安装到的位置>/gcc/15.1/bin:$PATH
export LD_LIBRARY_PATH=<你安装到的位置>/gcc/15.1/lib64:$LD_LIBRARY_PATHIMPORTANT
每次使用 GCC 15.1 前,都需要运行上述两条命令来激活它。
- 用 GCC 15.1 编译 OpenMPI 5.0.8
wget https://download.open-mpi.org/release/open-mpi/v5.0/openmpi-5.0.8.tar.gz
tar -xzf openmpi-5.0.8.tar.gz
mkdir openmpi-5.0.8/build && cd openmpi-5.0.8/build
export CFLAGS="-O3 -march=native -fno-plt -pipe"
export CXXFLAGS="$CFLAGS"
export FCFLAGS="$CFLAGS"
../configure --prefix=<你想安装到的位置>/openmpi/5.0.8-gcc15 \
--with-slurm \
--disable-debug \
--without-memory-manager \
--disable-dlopen \
--enable-mpi-fortran=all \
--enable-mpirun-prefix-by-default \
--with-wrapper-cflags="$CFLAGS" \
--with-wrapper-cxxflags="$CFLAGS" \
CC=<你安装GCC的位置>/gcc/15.1/bin/gcc \
CXX=<你安装GCC的位置>/gcc/15.1/bin/g++ \
FC=<你安装GCC的位置>/gcc/15.1/bin/gfortran
make -j$(nproc)
make install- 激活 OpenMPI 5.0.8
export PATH=<你安装到的位置>/openmpi/5.0.8-gcc15/bin:$PATH
export LD_LIBRARY_PATH=<你安装到的位置>/openmpi/5.0.8-gcc15/lib:$LD_LIBRARY_PATHIMPORTANT
每次使用 OpenMPI 5.0.8 前,都需要运行上述两条命令来激活它。
- 验证
mpicc --version # 应显示 "gcc version 15.1.0 ..."
mpirun --version # 应显示 "Open MPI 5.0.8"接着进入 CloverLeaf_SCC/ 并编译:
make COMPILER=GNU新建任务脚本 job.gnu.slurm,内容如下:
job.gnu.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48 # 可以更改
#SBATCH --ntasks-per-node=24 # 可以更改
#SBATCH --cpus-per-task=2 # 可以更改
#SBATCH --exclusive
# 注意:这里不能不继承环境变量,否则 slurmstepd 调不到 prted
# 注意:比赛环境为 2 节点,每节点 48 核
# 这意味着,cpus-per-task 乘以 ntasks-per-node 小于或等于 48 就可以了
# 这里有丰富的调参空间,欢迎尝试
lscpu
source ~/.bashrc
export PATH=<你安装GCC到的位置>/gcc/15.1/bin:$PATH
export LD_LIBRARY_PATH=<你安装GCC到的位置>/gcc/15.1/lib64:$LD_LIBRARY_PATH
export PATH=<你安装OpenMPI的位置>/openmpi/5.0.8-gcc15/bin:$PATH
export LD_LIBRARY_PATH=<你安装OpenMPI的位置>/openmpi/5.0.8-gcc15/lib:$LD_LIBRARY_PATH
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" clover.in
# Use Slurm-native launcher; mpirun also works if preferred
# srun --mpi=pmix -n "$NP" ./clover_leaf
mpirun -n "$NP" ./clover_leaf
mv clover.out "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fi然后提交任务:
sbatch job.gnu.slurm附录四:提交评测前检查
对于赛中评测,请确保你的仓库结构如下或者至少包含如下结构:
提交目录结构
CloverLeaf_SCC/ # 顶层文件夹(必须)
├── README.md # 可选,但如果存在 src_bonus/ 则必交:说明是什么版本,使用什么编译器
│
├── src_ref/ # 可选
│ └── … # 可选
│
├── src_bonus/ # 可选:Bonus CPU 版本源码(若有)
│ └── …
│
├── gnu/ # GNU 编译器跑分
│ ├── job.gnu.ref.slurm # 必交:ref 版本作业脚本
│ ├── job.gnu.bonus.slurm # 可选:bonus 版本作业脚本
│ ├── <job_id>_ref.out # 必交:ref 最佳输出(clover.out)
│ ├── <job_id>_ref.err # 可选:对应 stderr
│ ├── <job_id>_bonus.out # 可选:bonus 最佳输出
│ └── <job_id>_bonus.err # 可选
│
├── intel/ # Intel 编译器跑分
│ ├── job.intel.ref.slurm
│ ├── job.intel.bonus.slurm # 可选
│ ├── <job_id>_ref.out # 必交
│ ├── <job_id>_ref.err # 可选
│ ├── <job_id>_bonus.out # 可选
│ └── <job_id>_bonus.err # 可选
│
└── aocc/ # 可选:其他编译器(目录名自取)
├── job.aocc.ref.slurm # 若提交 ref 成绩则必填
├── job.aocc.bonus.slurm # 若提交 bonus 成绩则必填
├── <job_id>_ref.out # 可选
├── <job_id>_ref.err # 可选
├── <job_id>_bonus.out # 可选
└── <job_id>_bonus.err # 可选附录五:安装并使用 HPC-X
NVIDIA® HPC-X® 是一套功能全面的软件包,内含消息传递接口(MPI)、对称层次化共享内存(SHMEM)与分区全局地址空间(PGAS)通信库,以及多种加速组件。借助这一经过充分测试与打包的工具套件,MPI 与 SHMEM/PGAS 程序能够实现高性能、良好扩展性和高效率,并确保通信库在 NVIDIA Quantum InfiniBand 网络方案上得到充分优化。本次比赛中,HPC-X 作为 bonus 可选做,基准分数为 4 分(而不是 10 分)。
进入 HPC-X 官网,划到最底部,按照下图所示进行选择并下载: 
解压下载的压缩包,并进入解压后的目录。
tar -xvf hpcx-v2.21.3-gcc-doca_ofed-redhat8-cuda12-x86_64.tbz
cd hpcx-v2.21.3-gcc-doca_ofed-redhat8-cuda12-x86_64
export HPCX_HOME=$(pwd)但是我们不必安装了,因为 HPC-X 已经编译好了。
先加载之前安装好的 GCC 15.1:
export PATH=<你安装到的位置>/gcc/15.1/bin:$PATH
export LD_LIBRARY_PATH=<你安装到的位置>/gcc/15.1/lib64:$LD_LIBRARY_PATH加载环境:
source $HPCX_HOME/hpcx-init.sh
hpcx_load
env | grep HPCX # 确认环境变量已加载进入 CloverLeaf_SCC/ 目录,使用 HPC-X 编译 CloverLeaf:
make clean
make COMPILER=GNU MPI_COMPILER=mpifort C_MPI_COMPILER=mpicc
# 为什么这里是 GNU 呢?因为 HPC-X 原生支持 GNU 编译器!然而,在本次比赛中,我们还是把它单拎出来了。以相似的手段创建作业脚本 job.hpcx.slurm,这里不赘述了。
附录六:安装并使用 MVAPICH
MVAPICH 是一个高性能的 MPI 实现,专为 InfiniBand、Omni-Path 和以太网等高速网络设计。它在 HPC 社区中广泛使用,并提供了对多种网络接口的支持,由俄亥俄州立大学开发。本次比赛中,MVAPICH 作为 bonus 可选做,基准分数为 4 分(而不是 10 分)。
进入官网,按照下图进行选择,下载最新版本的 MVAPICH。 
下载完成后使用命令:
rpm2cpio mvapich-plus-4.1rc-nogpu.rhel8.ofed24.10.ucx.gcc13.2.0.slurm-4.1rc-1.el8.x86_64.rpm | cpio -id这时候发现多出来一个 opt 目录,里面包含了 MVAPICH 的所有文件。所以可以这样加载环境:
export MVAPICH_HOME=$(pwd)/opt/mvapich/plus/4.1rc/nogpu/ucx/slurm/gcc13.2.0
export PATH=$MVAPICH_HOME/bin:$PATH
export LD_LIBRARY_PATH=$MVAPICH_HOME/lib:$LD_LIBRARY_PATH此时,which mpicc 应该显示 xxx/opt/mvapich/plus/4.1rc/nogpu/ucx/slurm/gcc13.2.0/bin/mpicc。
mpicc 本身只是一个 MPI 编译器包装器,它最终会去调用某个真正的 C 编译器(缺省写成 gcc),再把 MPI 头文件和库的搜索路径附带进去。所以,你还需要按照附录三的方式加载 GCC 15.1。
这时候,执行 mpirun --version 发现 command not found,这是因为我们下载的 MVAPICH SLURM 版在构建时 只保留了 PMI-2/PMIx 启动机制,把自带的进程管理器(mpirun_rsh/hydra)全部关闭。因此包里只有编译器包装器 mpicc 和 mpifort,而 没有 mpirun/mpiexec 可执行文件,这完全正常。我们只需要用 srun 而不是 mpirun 来启动 MPI 程序。比如:
srun --mpi=pmi2 -n "$NP" ./clover_leaf接下来,用 make COMPILER=GNU 编译 CloverLeaf,然后撰写作业脚本提交任务即可。
在 make 的时候有可能遇到报错:
Warning: Nonexistent include directory '/opt/mvapich/plus/4.1rc/nogpu/ucx/slurm/gcc13.2.0/include'这是因为我们是从 rpm 包安装的,它会默认我们有 root 权限。一个简单的解决方法就是修改 Makefile。先对 Makefile 进行备份,然后在
FLAGS=$(FLAGS_$(COMPILER)) $(OMP) $(I3E) $(OPTIONS)
CFLAGS=$(CFLAGS_$(COMPILER)) $(OMP) $(I3E) $(C_OPTIONS) -c
MPI_COMPILER=mpif90
C_MPI_COMPILER=mpicc后面加上:
MPI_HOME ?= <安装位置>/opt/mvapich/plus/4.1rc/nogpu/ucx/slurm/gcc13.2.0
FLAGS+= -L$(MPI_HOME)/lib
CFLAGS+= -L$(MPI_HOME)/lib
FLAGS += -I$(MPI_HOME)/include
CFLAGS += -I$(MPI_HOME)/include这样虽然会报 Warning,但不会影响编译。
编译完成之后,由于计算节点上没有安装 libpciaccess 和 slurm-libpmi,所以一个非常粗暴的做法就是:
cp /usr/lib64/libpciaccess.so.0 <CloverLeaf所在位置>
cp /usr/lib64/libpmi.so.0 <CloverLeaf所在位置>然后作业脚本里面加上
export LD_LIBRARY_PATH=<CloverLeaf所在位置>:$LD_LIBRARY_PATH示例作业脚本如下(记得改路径):
job.mvapich.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48 # 可以更改
#SBATCH --ntasks-per-node=24 # 可以更改
#SBATCH --cpus-per-task=2 # 可以更改
#SBATCH --export=ALL
#SBATCH --exclusive
lscpu
source ~/.bashrc
export PATH=/work/ccse-xiaoyc/xqw/baomu/gcc/15.1/bin:$PATH
export LD_LIBRARY_PATH=/work/ccse-xiaoyc/xqw/baomu/gcc/15.1/lib64:$LD_LIBRARY_PATH
export MVAPICH_HOME=/work/ccse-xiaoyc/xqw/opt/mvapich/plus/4.1rc/nogpu/ucx/slurm/gcc13.2.0
export PATH=$MVAPICH_HOME/bin:$PATH
export LD_LIBRARY_PATH=$MVAPICH_HOME/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/work/ccse-xiaoyc/xqw/baomu/CloverLeaf_SCC:$LD_LIBRARY_PATH
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" clover.in
# Use Slurm-native launcher; mpirun also works if preferred
srun --mpi=pmi2 -n "$NP" ./clover_leaf
# mpirun -n "$NP" ./clover_leaf
mv clover.out "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fi附录七:安装并使用 MPICH
重要更新
2025/7/24:更新了 ./configure 的选项,增加了 --with-device=ch4:ucx 和 --with-ucx=/usr 等,以确保 MPICH 使用 UCX 作为通信协议。
MPICH 是阿贡国家实验室 (Argonne National Laboratory) 发布的高性能、可广泛移植的 MPI-4.1 标准实现。此版本具备该标准所需的所有 MPI 4.1 功能和特性,但不支持用户定义的 I/O 数据表示,是很多研究 MPI 特性的基线。本次比赛中,MPICH 作为 bonus 可选做,基准分数为 4 分(而不是 10 分)。
进入官网,选择下载 mpich-4.3.1 (stable release) 。
wget https://www.mpich.org/static/downloads/4.3.1/mpich-4.3.1.tar.gz
tar -xzf mpich-4.3.1.tar.gz
cd mpich-4.3.1
# 这里需要指定通信协议
./configure --prefix=<你想安装到的目录>/mpich \
--with-device=ch4:ucx \
--with-ucx=/usr \
--enable-fast=all,O3 \
--enable-thread-cs=per-vci \
--enable-shared
make -j$(nproc) && make install配置环境变量:
export PATH=<你安装到的目录>/mpich/bin:$PATH
export LD_LIBRARY_PATH=<你安装到的目录>/mpich/lib:$LD_LIBRARY_PATH
export MANPATH=<你安装到的目录>/mpich/man:$MANPATH进入 CloverLeaf_SCC/ 目录,使用 MPICH 编译 CloverLeaf:
make COMPILER=GNU示例作业脚本如下(记得改路径):
job.mpich.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48 # 可以更改
#SBATCH --ntasks-per-node=24 # 可以更改
#SBATCH --cpus-per-task=2 # 可以更改
# 注意:比赛环境为 2 节点,每节点 48 核
# 这意味着,cpus-per-task 乘以 ntasks-per-node 小于或等于 48 就可以了
# 这里有丰富的调参空间,欢迎尝试
lscpu
source ~/.bashrc
export PATH=/work/ccse-xiaoyc/opt/mpich/bin:$PATH
export LD_LIBRARY_PATH=/work/ccse-xiaoyc/opt/mpich/lib:$PATH
export MANPATH=/work/ccse-xiaoyc/opt/mpich/man:$MANPATH
export LD_LIBRARY_PATH=/work/ccse-xiaoyc/xqw/baomu/CloverLeaf_SCC:$LD_LIBRARY_PATH
which mpicc
which gcc
which gfortran
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" clover.in
# Use Slurm-native launcher; mpirun also works if preferred
# srun --mpi=list
# srun --mpi=pmi_v3 -n "$NP" ./clover_leaf
# mpirun -n "$NP" ./clover_leaf
mpiexec -bind-to core -map-by socket -n "$NP" ./clover_leaf
mv clover.out "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fi附录八:安装并使用 NVIDIA HPC SDK
NVIDIA HPC SDK C、C++ 和 Fortran 编译器支持使用标准 C++ 和 Fortran、OpenACC® 指令以及 CUDA® 对 HPC 建模和仿真应用程序进行 GPU 加速。GPU 加速数学库可最大程度提升常见 HPC 算法的性能,而优化的通信库则支持基于标准的多 GPU 和可扩展系统编程。性能分析和调试工具可简化 HPC 应用程序的移植和优化,而容器化工具则可轻松实现本地或云端部署。HPC SDK 支持 NVIDIA GPU 以及运行 Linux 的 Arm 或 x86-64 CPU,可提供构建 NVIDIA GPU 加速 HPC 应用程序所需的工具。本次比赛中这个赛题不会提供 GPU,但 NVIDIA HPC SDK 也可以在 没有 GPU 的机器上安装,只是 GPU 专属库(cuBLAS、cuFFT 等)和 Nsight Compute/Systems 无法运行。NVHPC 基准分数为 4 分(而不是 10 分)。
下载并安装:
wget https://developer.download.nvidia.com/hpc-sdk/25.5/nvhpc_2025_255_Linux_x86_64_cuda_12.9.tar.gz
tar xpzf nvhpc_2025_255_Linux_x86_64_cuda_12.9.tar.gz
nvhpc_2025_255_Linux_x86_64_cuda_12.9/install # 注意要选 Network Install安装完成后,命令行中会显示配置环境变量的方法,建议记下来。比如,如果你喜欢使用 module load,那么命令大概是:
module load <xxx>/modulefiles/nvhpc/25.5编译 CloverLeaf:
make COMPILER=PGI然而,PGI 被 NVIDIA 收购之后,nvfortran >= 24.x 把 PGI 时代的 -Mipa 家族全部合并进新 IP 优化管线,如果你收到了下面的警告:
nvfortran-Warning-The option -Mipa has been deprecated and is ignored你可以把 -Mipa=fast 改为 -O3。
示例作业脚本如下(记得改路径):
job.nvhpc.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48 # 可以更改
#SBATCH --ntasks-per-node=24 # 可以更改
#SBATCH --cpus-per-task=2 # 可以更改
#SBATCH --export=ALL
#SBATCH --exclusive
# 注意:比赛环境为 2 节点,每节点 48 核
# 这意味着,cpus-per-task 乘以 ntasks-per-node 小于或等于 48 就可以了
# 这里有丰富的调参空间,欢迎尝试
lscpu
source ~/.bashrc
module purge
export NVHPC_ROOT=/work/ccse-xiaoyc/xqw/nvhpc
module use $NVHPC_ROOT/modulefiles
module load nvhpc-hpcx
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" clover.in
# Use Slurm-native launcher; mpirun also works if preferred
# srun --mpi=list
# srun --mpi=pmi_v3 -n "$NP" ./clover_leaf
mpirun -n "$NP" ./clover_leaf
mv clover.out "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fi附录九:OMP_NUM_THREADS 对性能的影响
在使用 OpenMP 进行并行计算时,OMP_NUM_THREADS 环境变量指定了每个 MPI 进程使用的线程数。合理设置这个值可以显著提高性能,但过高或过低都可能导致性能下降。在提供的作业脚本中,OMP_NUM_THREADS 被设置为 SLURM_CPUS_PER_TASK 的值,这通常是每个任务分配的 CPU 核心数。更改 --cpus-per-task 参数即调整 OMP_NUM_THREADS 的值。
下面以 Intel 编译器在 case 2 上为例,展示 OMP_NUM_THREADS 对性能的影响。
| OMP_NUM_THREADS | 运行时间 |
|---|---|
| 1 | 8.17500805854797 s |
| 2 | 7.92250204086304 s |
| 4 | 7.98454308509827 s |
| 8 | 8.02640581130981 s |
| 16 | 9.08874893188477 s |
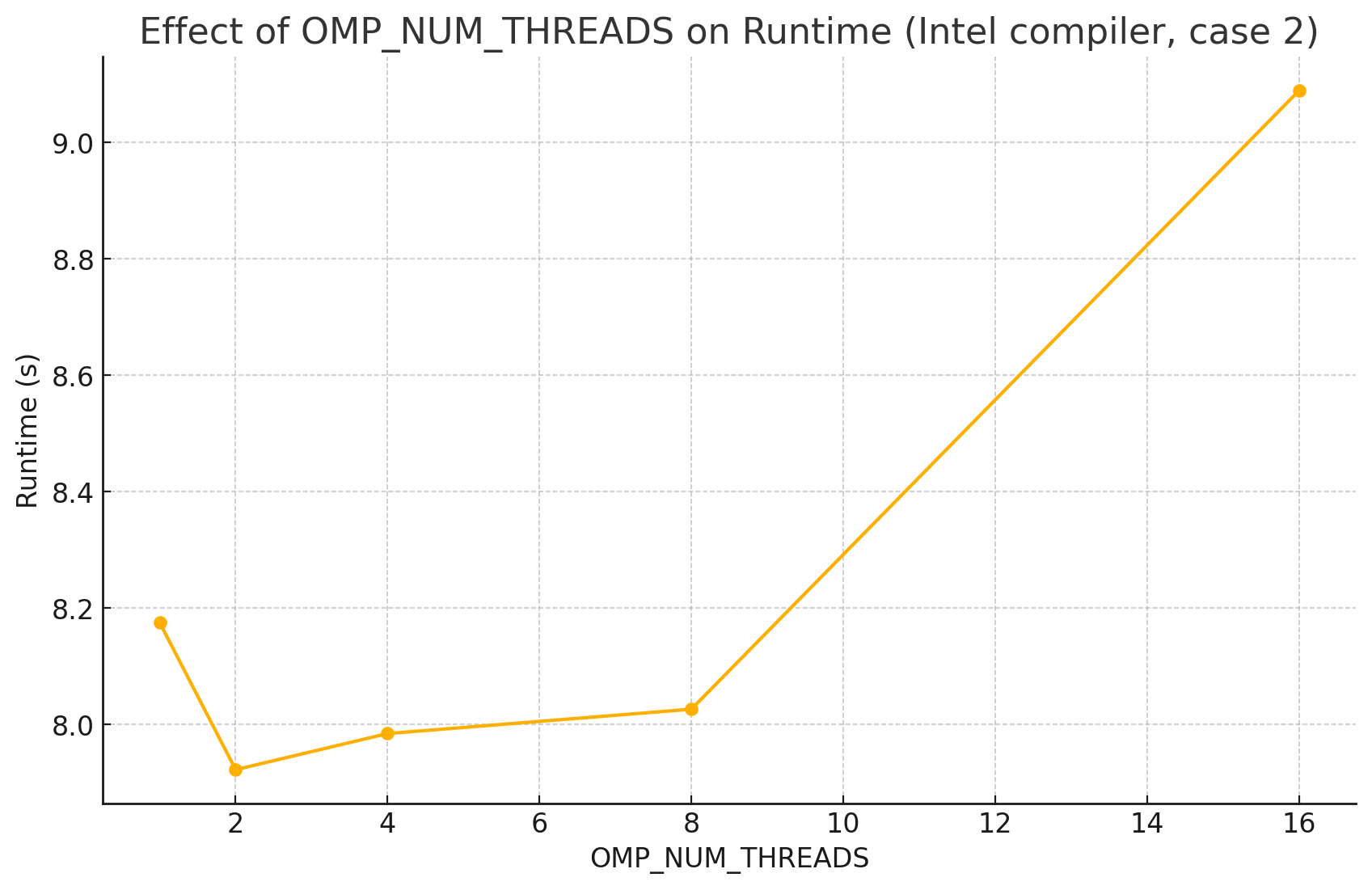
也许?
如果你能在报告中展示 OMP_NUM_THREADS 对其他编译器(如 GNU、AOCC、NVHPC 等)的影响,那就更好了!
附录十:核数对性能的影响
下面以 Intel 编译器在 case 2 上为例,展示核数对性能的影响。(OMP_NUM_THREADS=2)
| 总核心数 | 1个节点 | 2个节点 |
|---|---|---|
| 8 | 64.5869278907776 s | 61.6611549854279 s |
| 16 | 33.7711331844330 s | 32.0495719909668 s |
| 32 | 19.7675180435181 s | 17.2381088733673 s |
| 48 | 16.0617241859436 s | 12.2575910091400 s |
| 64 | 每节点最多48核 | 9.98219609260559 s |
| 96 | 每节点最多48核 | 7.92250204086304 s |
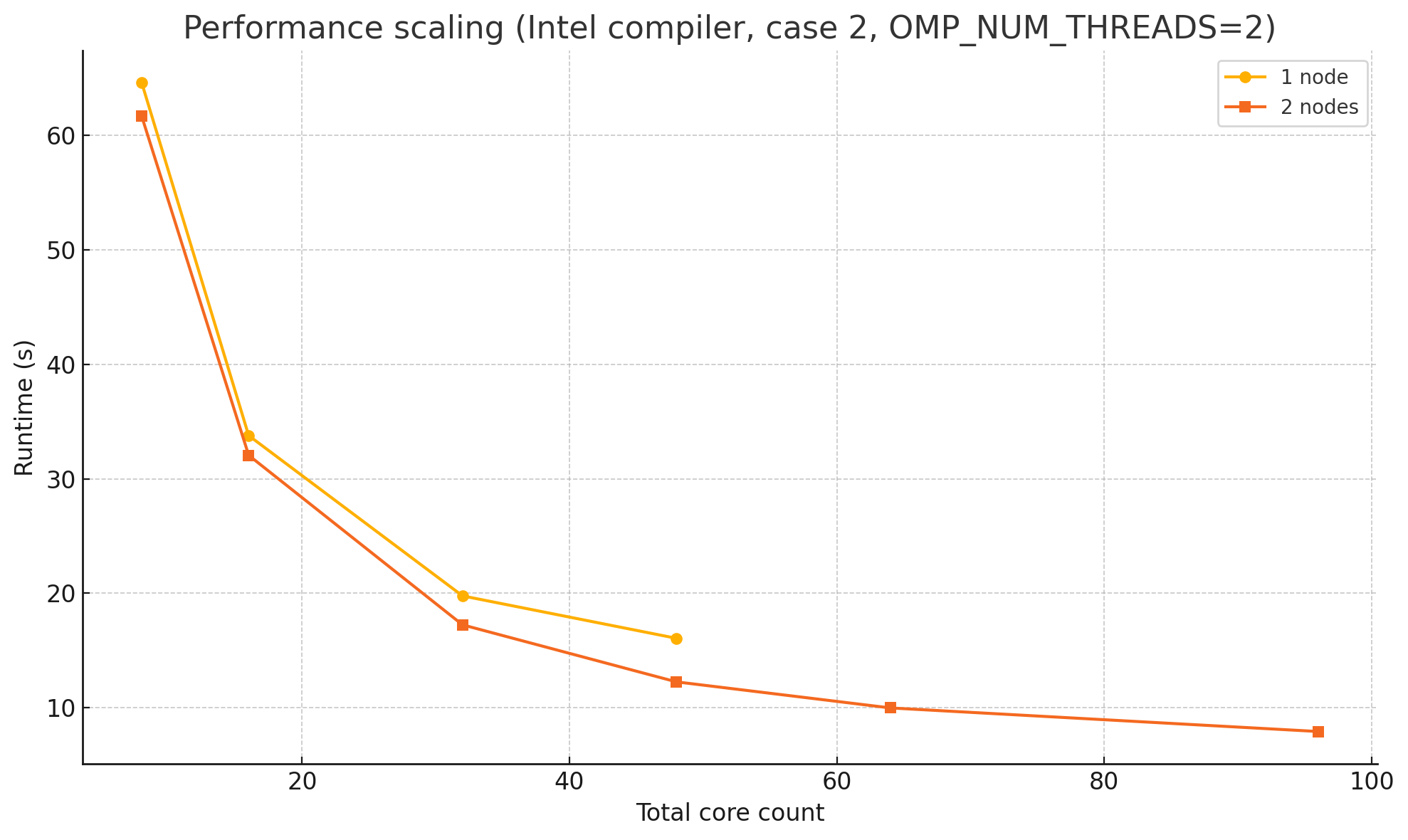
从 8 到 32 核,两条曲线都几乎按理想比例下降:当核心数翻倍,运行时间大约减半,说明计算部分仍是可并行的、通信压力也不高。单节点在 48 核附近触及硬件上限,继续增核只能依赖 SMT,增益有限;而把任务拆到第二节点后,64 核与 96 核仍能显著缩短时间,但加速比已不足线性,原因是跨节点通信、远端内存访问和调度开销开始占优。
同样的总核心数拆成双节点后反而更快,主要是因为内存子系统的资源翻倍,而通信开销并没有同比增长。
在单节点里,所有核心共用同一块内存控制器和有限的 L3/L2 缓存,竞争激烈;一旦任务属于内存绑定型,核心大部分时间都在等待数据。把一半核心挪到另一台节点,相当于额外获得了一套独立的内存控制器、完整的缓存层级以及更宽的总线带宽。每个核心可用的有效 DRAM 带宽几乎加倍,缓存冲突率也随之下降,等待时间显著缩短。
至于跨节点的 MPI 通信,它在这个案例中体量不大、延迟容忍度又高,几十微秒的网络往返不足以抵消内存加速带来的收益。另外,单节点把所有物理核心都跑满时,CPU 为了控制功耗往往会降频;分成两台机器后,每个 CPU 只用一半核心,能维持更接近睿频的时钟,也进一步拉开了差距。
综合来看,双节点配置凭借更高的可用内存带宽、更大的有效缓存和略高的核心频率,即便在相同的总核心数下,也能跑出更短的总时间。
也许?
如果你能在报告中展示不同编译器(如 GNU、AOCC、NVHPC 等)在不同核数下的性能变化,那就更好了!
附录十一:性能分析
Intel MPI 内置统计
在 mpirun 之前加上:
export I_MPI_STATS=5 # 0=off, 1~10 越大信息越多作业结束后就会看到一个 aps_result_YYYYMMDD_HHMMSS/ 目录,执行
aps-report aps_result_YYYYMMDD_HHMMSS # 纯文本报告
# 或
aps --report aps_result_YYYYMMDD_HHMMSS # 生成 HTML,可浏览器查看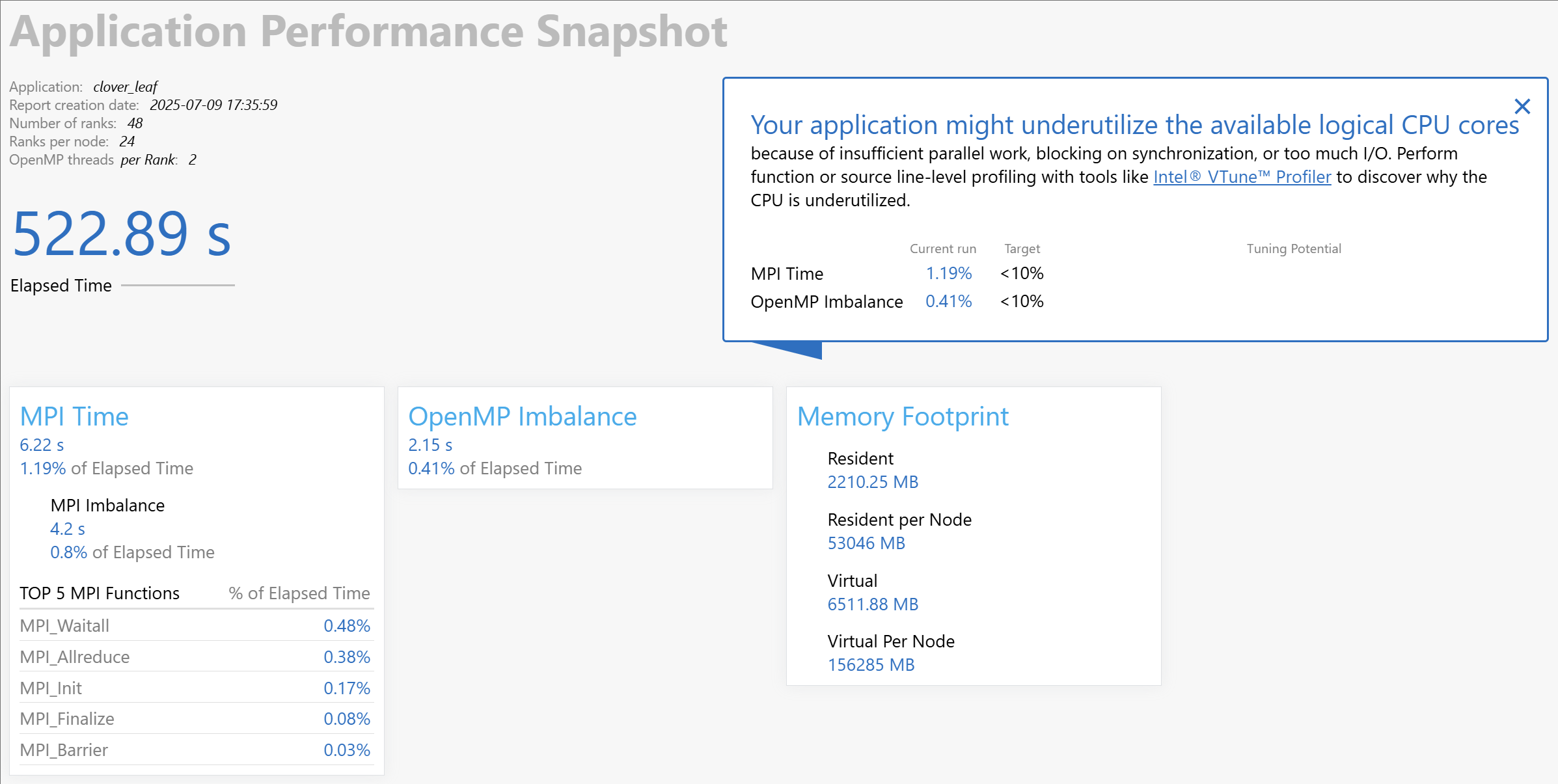
这份 APS 摘要说明,真正拖慢总运行时间的,不是 MPI 通信,也不是 OpenMP 线程等待,而是核内计算效率:
- MPI 只占 1.19 %,其中等待不平衡(Imbalance)仅 0.8 %。Allreduce 和 Waitall 的累计时间加起来不到 4.5 秒,表明跨进程同步基本不会限制扩展性。
- OpenMP 不平衡占 0.41 %,说明 2 个线程/Rank 的并行区大体均衡;线程间的 idle 很少,不必从再调 OMP_NUM_THREADS角度着手。
- CPU 利用率仍然偏低。APS 直接给出提示:“可能计算负载不足、同步过频或 I/O 过多导致逻辑核心未被充分利用”。既然 MPI 和 OpenMP 等候时间都很小,可排除同步过频;I/O 时间计为 0,也排除过多 I/O。剩下唯一合理解释是核心在算术或访存阶段效率不高——要么内存带宽受限,要么向量化程度不足,要么两者兼有。
- 内存占用:每节点常驻 53 GB,远未逼近常见 192 GB-512 GB 的节点内存上限;每 Rank 常驻 2.2 GB。说明单条数据就能完整放进内存,CPU 仍旧等数据,更像带宽或缓存命中率问题,而非容量不足。
Intel VTune Profiler
DANGER
VTune 暂时缺少某个驱动,有些功能无法使用
那么接下来,我们采用更加强力的 Intel VTune Profiler 进行性能分析。
首先带上 -g 重新编译 CloverLeaf,做法是在 CFLAGS_INTEL 和 FLAGS_INTEL 中添加 -g 选项,然后
make COMPILER=INTEL MPI_COMPILER=mpiifort C_MPI_COMPILER=mpiicc然后把 job.intel.slurm 中的 mpirun 命令改为:
export VTUNE_PROFILER_LOG_DIR=$HOME/.vtune-logs
mkdir -p $VTUNE_PROFILER_LOG_DIR
which vtune # 路径应指向 oneAPI/vtune/bin64/vtune
vtune --version # 打印版本号
vtune --help collect # 能列出全部 analysis types
vtune -collect memory-access -result-dir vtune_${SLURM_JOB_ID} -- mpirun -n $SLURM_NTASKS ./clover_leaf
# 这里 memory-access 是分析类型,其他类型可参考 `vtune --help collect` 的输出
vtune -collect hotspots -result-dir vtune_${SLURM_JOB_ID} -- mpirun -n $SLURM_NTASKS ./clover_leaf
# 也可以去收集热点信息收集完后生成报告:
vtune -report summary -result-dir vtune_${SLURM_JOB_ID} > vtune_summary.txt
vtune -report hotspots -result-dir vtune_${SLURM_JOB_ID} > vtune_hotspots.txt
vtune -report memory-access -result-dir vtune_${SLURM_JOB_ID} > vtune_memory_access.txtgprof
如果你使用 GNU 编译器,可以使用 gprof 进行性能分析。
首先,确保在编译时启用了 -pg 选项,可以在 CFLAGS_GNU 和 FLAGS_GNU 中添加 -pg,并暂时把优化等级调为 -O2。然后重新编译 CloverLeaf:
make COMPILER=GNU编译完成后,修改 job.gnu.slurm 中的 mpirun 命令为:
# `GMON_OUT_PREFIX` 能让每个 rank 写成 gmon.<rank>.<pid>,避免互相覆盖。
mpirun -n "$NP" env GMON_OUT_PREFIX="gmon.$SLURM_PROCID." ./clover_leaf
# 把所有 gmon.* 累加进 gmon.sum
gprof -s ./clover_leaf gmon.*
# 再生成汇总报告
gprof ./clover_leaf gmon.sum > report_all.txt如果想要可视化:
pip install gprof2dot graphviz
gprof2dot -f gprof report_all.txt | dot -Tpng -o callgraph.png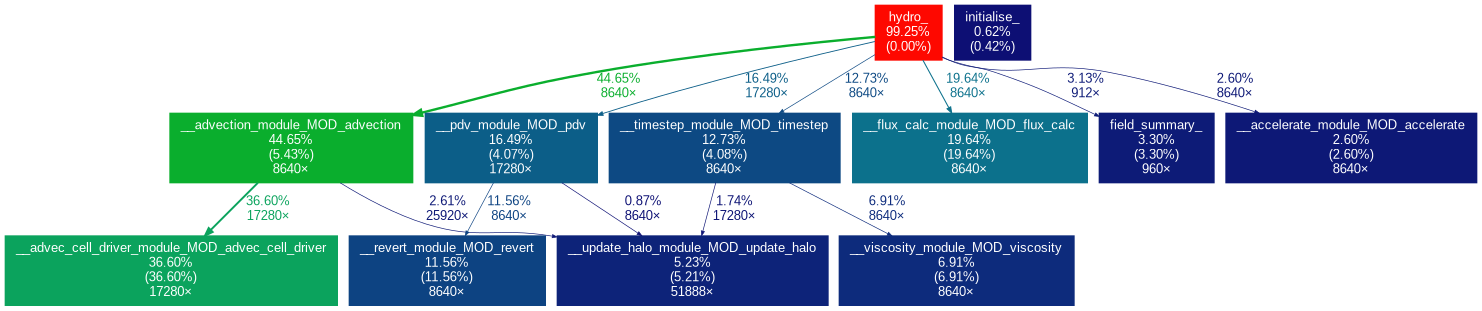
再针对热点函数进行优化。
附录十二:Roofline 分析
| 记号 | 含义 | 典型单位 |
|---|---|---|
| P_peak | 计算峰值 | GFLOP/s |
| B_peak | 主存带宽峰值 | GB/s |
| I = F/B | 算术强度 (Arithmetic Intensity) | FLOP / Byte |
Roofline 模型 (‐Williams 2009) 把一台机器的计算天花板
这能够画成一条屋顶一样的线:
- 水平线:FMA/ADD 峰值吞吐
- 倾斜线:带宽 x I
- 应用核在坐标
处落点 - 落在斜线上:memory-bound
- 落在水平线附近:compute-bound
- 位于两线之间:可能由缓存/并发限制
总的来说,在现代处理器上,代码性能既受计算单元吞吐限制,也受内存子系统带宽限制。Roofline 模型把这两种极限画成一条水平线(浮点峰值)和一条向上的斜线(带宽 x 算术强度)。坐标系的横轴是算术强度,即每搬运一个字节数据能够完成多少次浮点运算;纵轴是实际获得的 GFLOP/s。只要把内核测得的 (FLOP/Byte, GFLOP/s) 点放到图上,就能直观判断它究竟受哪条屋顶限制:落在倾斜带宽线附近说明主体瓶颈是内存,落在水平峰值附近才意味着真正的计算受限,其余情况往往是缓存局部性或并发效率没有发挥出来。
在 oneAPI 环境中,只需要一条命令就能让 Advisor 完成两轮分析:Survey 用来统计热点及指令数量,Trip Counts & FLOP 则计量访存字节与实际 FLOPs。示例命令如下(以 case2 为例):
job.intel.advisor.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=24
#SBATCH --export=NONE
#SBATCH --exclusive
source ~/.bashrc
source /work/share/intel/oneapi-2023.1.0/setvars.sh
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
cp "cases/case2/clover.in" clover.in
numactl -C 0-23 -m 0 \
rm -rf ./adv_proj
advisor --collect=roofline \
--project-dir=./adv_proj \
-- ./clover_leaf > run.out 2>&1
advisor --report=roofline --project-dir=./adv_proj \
--format=csv --report-output=roofline.html
advisor --report=roofline --project-dir=./adv_proj可以生成 HTML 文件,或者直接用 advisor-gui 打开可视化界面浏览那张屋顶图。
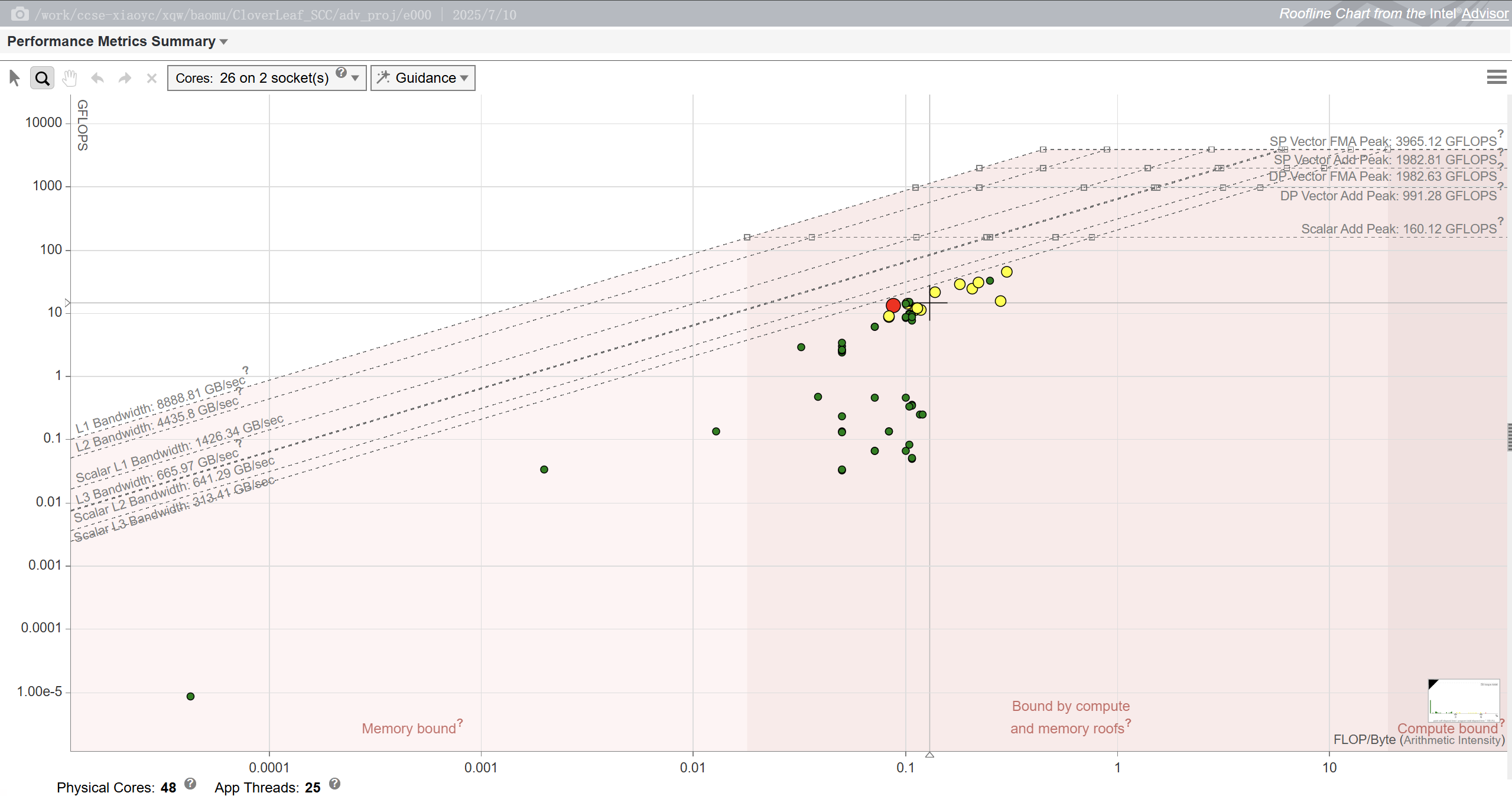
我们针对 CloverLeaf 使用 3840x3840 的网格和 24 条线程进行了采样。图中所有热点循环的算术强度都集中在 0.07 到 0.18 FLOP/Byte 之间,也就是说每加载一条 64 字节的缓存行,只做几次浮点运算就得继续访存。这类密度远低于 Skylake-SP 拐点所需的三四 FLOP/Byte,因此它们天然是内存型代码。从纵坐标来看,最热的几个循环只能跑到 10 到 20 GFLOP/s,而同一节点的双精度向量 FMA 峰值接近 2000 GFLOP/s,显然计算单元几乎是空闲的。
更值得注意的是,这些点并没有贴在 DRAM 带宽屋顶上,而是在其下方约一半的位置。也就是说,带宽并非被硬件极限卡死,而是访问模式、NUMA 亲和或不规则 stride 让有效带宽损失了一半。这也能解释为什么即使我尝试手工写 AVX 指令,运行时间几乎没变,因为瓶颈根本不在算术吞吐。如果把内核迁移到有 HBM 或 GPU 的更高带宽平台,往往能一次性把性能提升一个量级。后续优化应聚焦于访存模式、NUMA 亲和和数据布局,而非堆砌指令级并行。
也许?
如果你能在报告中展示不同情况下的 Roofline 分析结果,那就更好了!
这其实能部分解释为什么 MVAPICH 比 GNU+OpenMPI 快很多。先回到 Roofline 那张图,那张图说的是节点内部的算术和访存关系,算术单元空闲而内存带宽成为第一瓶颈。也就是说,只要数据已经在本地内存里,换成更强的矢量指令或者更快的 CPU 并不会把时间缩短很多。
MPI 库的差别属于另一条链路:节点间通信。CloverLeaf 每一次 X-或 Y-sweep 都要做 halo 交换:把边界两列(或两行)的密度、能量、质量通量发给相邻进程。网格越大、进程越多,通信-计算重叠做得好不好就越重要。这里就轮到 MPI 实现出场了。MVAPICH 针对 IB/RDMA 做了零拷贝 pipeline、长消息 rendezvous、短消息 eager RDMA,再加上后台异步进展线程,能够实打实把带宽做满、把延迟压低;OpenMPI 如果用默认 UCX 或 ob1‐openib 路径,长消息通常走 copy-in/copy-out rendezvous,短消息走 eager 拷贝,再加上没有启用异步进展,很容易在 MPI_Waitall 上把核心挂住。
其实,整套应用运行时间可以写成两块相加:
T_total = T_compute_on_node + T_wait_for_haloRoofline 帮助我们看清 T_compute_on_node;而 MVAPICH 快一倍说明 T_wait_for_halo 在 OpenMPI 版本里成了主导,而 MVAPICH 把这部分压得更低,所以整体速度翻番。
也许?
运用附录十一中给出的 MPI 性能分析,看看时间线里 MPI_Waitall 的占比,GNU+OpenMPI 版本是比 MVAPICH 更高还是更低?这与理论一致吗?
也许?
给 OpenMPI 明确指定 UCX/ob1 + openib 的参数并开启异步进展:
--mca pml ucx \
--mca btl_openib_allow_ib 1 \
--mca btl_openib_want_fork_support 0 \
--mca mpi_leave_pinned 1 \
--mca opal_progress 1000同样让 GCC 编译版本加上 -march=skylake-avx512 -flto,不要只用默认 -O3。这样会更快了吗?
附录十三:使用 Spack 管理依赖
Spack 是一款软件包管理工具,旨在支持各种平台和环境下的多种软件版本和配置。它专为大型超级计算中心而设计,在这些中心,许多用户和应用程序团队使用不具备标准 ABI 的库,在架构各异的集群上共享通用的软件安装。Spack 具有非破坏性:安装新版本不会破坏现有安装,因此多种配置可以在同一系统上共存。
安装 Spack
cd ~
git clone https://github.com/spack/spack
source ~/spack/share/spack/setup-env.sh注意
提交的作业脚本中也需要添加 source ~/spack/share/spack/setup-env.sh,以确保 Spack 环境变量正确设置。
使用 Spack 安装并使用 CloverLeaf
这里先安装一个 oneAPI 套件的版本:
spack install cloverleaf-ref@1.3 %oneapi ^intel-oneapi-mpi%oneapi 指定用 oneAPI 编译所有东西,一些常见的选项还有 %gcc、%intel、%nvhpc 等。
^intel-oneapi-mpi 指定使用 Intel 的 MPI 实现,一些常见的实现选项有 ^openmpi、^mvapich2、^mpich 等。
出现 cloverleaf-ref: Successfully installed cloverleaf-ref-1.3-.... 则说明安装成功。
从此以后,就可以使用
spack load cloverleaf-ref@1.3 %oneapi来加载 CloverLeaf 的环境了。
但是由于计算节点上没有 git,所以我们得先自己安装一个:
curl -L https://github.com/git/git/archive/refs/tags/v2.45.2.tar.gz | tar xzf -
cd git-2.45.2
make prefix=$HOME/opt/git install然后在作业脚本中加入:
export PATH=$HOME/opt/git/bin:$PATH注意
clover_leaf 的输入文件是从工作目录的 clover.in 中读取的。
示例作业脚本如下:
job.intel.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48
#SBATCH --ntasks-per-node=24 # 更改
#SBATCH --cpus-per-task=2 # 可以更改
#SBATCH --export=NONE
#SBATCH --exclusive
# 注意:比赛环境为 2 节点,每节点 48 核
# 这意味着,cpus-per-task 乘以 ntasks-per-node 小于或等于 48 就可以了
# 这里有丰富的调参空间,欢迎尝试
lscpu
source ~/.bashrc
export PATH=$HOME/opt/git/bin:$PATH
source ~/spack/share/spack/setup-env.sh
spack load cloverleaf-ref@1.3 %oneapi
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{2..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
EXE=$(which clover_leaf)
EXE_DIR=$(dirname "$EXE")
cp "cases/case${i}/clover.in" .
mpirun -n "$NP" "$EXE"
mv "clover.out" "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fiSpack 与编译选项优化
Spack 提供给我们了编译器,我们也可以自己来编译 CloverLeaf。spack load cloverleaf-ref@1.3 %oneapi 之后,执行
which mpiifx
which mpiicx都有输出,说明用上了 oneAPI 最新的编译器。
注意
mpiicx 并不完全兼容 mpiicc,迁移指南请见:Porting Guide for ICC Users to DPCPP or ICX.
注意
最新的 icx 不一定比 icc 快,比如 Intel ICX C++ compiler often generates slower code.
编译 CloverLeaf:
make COMPILER=INTEL MPI_COMPILER=mpiifx C_MPI_COMPILER=mpiicx再把作业脚本改回去:
job.intel.slurm
#!/bin/bash
#SBATCH --partition=8175m
#SBATCH --time=24:00:00
#SBATCH --job-name=cloverleaf
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --ntasks=48
#SBATCH --ntasks-per-node=24 # 更改
#SBATCH --cpus-per-task=2 # 可以更改
#SBATCH --export=NONE
#SBATCH --exclusive
# 注意:比赛环境为 2 节点,每节点 48 核
# 这意味着,cpus-per-task 乘以 ntasks-per-node 小于或等于 48 就可以了
# 这里有丰富的调参空间,欢迎尝试
lscpu
source ~/.bashrc
export PATH=$HOME/opt/git/bin:$PATH
source ~/spack/share/spack/setup-env.sh
spack load intel-oneapi-compilers@2023.1.0
spack load intel-oneapi-mpi@2021.16.0
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-8}
export OMP_PLACES=cores
export OMP_PROC_BIND=close
NP=${SLURM_NTASKS:-32}
get_ke () {
grep -E '^[[:space:]]*step:' "$1" | tail -1 | \
awk '{printf "%.10e\n", $(NF-1)}'
}
get_wc () {
grep -E 'Wall[[:space:]]+clock' "$1" | tail -1 | awk '{print $(NF)}'
}
PASS_CNT=0
FAIL_CNT=0
declare -A WCTIMES
printf "\n=== Correctness Check ===\n"
printf "Num proc: %d\n\n" "$NP"
CASES="{1..2}"
for i in $(eval echo $CASES); do
printf "? Case %-2d : Simulating...\n" "$i"
cp "cases/case${i}/clover.in" .
mpirun -n "$NP" ./clover_leaf
mv "clover.out" "clover${i}.out"
ref_file="cases/case${i}/clover.out"
my_ke=$(get_ke "clover${i}.out")
ref_ke=$(get_ke "$ref_file")
rel_err=$(awk -v a="$my_ke" -v b="$ref_ke" 'BEGIN{print (a-b>0? a-b: b-a)/b}')
rel_pct=$(awk -v e="$rel_err" 'BEGIN{printf "%.4f", e*100}')
wc_time=$(get_wc "clover${i}.out")
WCTIMES[$i]=$wc_time
if awk -v e="$rel_err" 'BEGIN{exit !(e<=0.005)}'; then
printf " ✔ Passed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
echo " ⏱ Wall clock = ${wc_time}s"
((PASS_CNT++))
else
printf " ✘ Failed (ref=%s, out=%s, eps=%s%%)\n" "$ref_ke" "$my_ke" "$rel_pct"
((FAIL_CNT++))
fi
echo
done
printf "=== Summary ===\n"
printf "Passed: %d, Failed: %d\n" "$PASS_CNT" "$FAIL_CNT"
echo -e "\nWall clock per case:"
for i in $(eval echo $CASES); do
printf " Case %-2d : %s s\n" "$i" "${WCTIMES[$i]:-NA}"
done
if (( FAIL_CNT == 0 )); then
printf "✅ All cases passed within 0.5%% tolerance.\n"
else
printf "⚠️ Some cases failed. Please investigate.\n"
exit 1
fi提示
由于 Intel 的 baseline 性能过好,如果想要收益更大的话,可以尝试用 Spack 安装 GNU 编译器或者 AOCC 编译器,然后编译 CloverLeaf。
附录十四:CloverLeaf 各项参数解释
CloverLeaf 的源码是允许修改的,只要通过正确性检验就可以。甚至 read_input.f90 里面的参数都可以改,但是有些参数会被 clover.in 覆写而 clover.in 是不允许修改的。下面解释一下 read_input.f90 中的各项参数。
网格 (grid)
| 名称 | 典型含义 | 这里的取值 |
|---|---|---|
grid%xmin, grid%ymin | 计算域左下角的物理坐标 (xmin, ymin) | 0.0;说明左下角在原点 |
grid%xmax, grid%ymax | 计算域右上角坐标 (xmax, ymax) | 100.0;说明域长、域宽都是 100 个长度单位 |
grid%x_cells, grid%y_cells | 在 x、y 方向把整个域划分多少个 逻辑单元(cell) | 10 × 10 ⇒ 每个 cell 尺寸 = 10.0×10.0 |
提示 如果你把
x_cells、y_cells成倍加密到 100×100、1000×1000,域的几何尺寸不变,但数值精度提高,计算量也相应增加。
终止条件
| 名称 | 功能 | 取值解释 |
|---|---|---|
end_time | 物理时间终点(流体演化到多少秒就停) | 10.0 |
end_step | 数值迭代步上限 | g_ibig 是一个特大整数常量(≈ 2 × 109)。这里等于「几乎不限制步数」,相当于以 end_time 为准 |
complete | 若为 .TRUE. 表示此输入文件已完成一次运行,用于重启脚本判定 | 现在是 .FALSE. — 正常新起一跑 |
输出频率
| 名称 | 用途 | 当前取值 |
|---|---|---|
visit_frequency | 每隔多少步把场数据写成 VisIt 可视化文件(.silo) | 0 ⇒ 不输出 |
summary_frequency | 每隔多少步在终端/日志打印能量、动量等摘要行 | 10 ⇒ 每 10 步汇报一次 |
并行切分
| 名称 | 含义 | 说明 |
|---|---|---|
tiles_per_chunk | 一个 MPI 子域 (chunk) 内包含的 tile 数 | 1 代表 “不再细切”,常见于 CPU-only 小规模基准。若改成 4、8 等,可结合 OpenMP 并行 |
时间步长控制 (CFL / 物理稳定性)
| 参数 | 作用与常见公式 | 当前值 |
|---|---|---|
dtinit | 初始猜测时间步 Δt0 | 0.1 |
dtmax | Δt 的绝对上限(防止 CFL 条件被粗粒度时间步破坏) | 1.0 |
dtmin | Δt 的绝对下限(防止陷入过小步耗时太多) | 1.0 × 10-7 |
dtrise | 自动放大 Δt 的倍率——每步最多乘以 dtrise(常称 timestep rise factor) | 1.5 |
dtc_safe | 声速 CFL 安全系数 (Δt ≤ dtc_safe · Δx / c) | 0.7 |
dtu_safe | x 方向流速 CFL 系数 (Δt ≤ dtu_safe · Δx / u) | 0.5 |
dtv_safe | y 方向流速 CFL 系数 (Δt ≤ dtv_safe · Δy / v) | 0.5 |
dtdiv_safe | 体积变化率(∇·u)安全系数 | 0.7 |
附录十五:可视化结果
将 visit_frequency 改为非 0 的值(如 10),然后重新编译运行,CloverLeaf 会在每隔 visit_frequency 步后生成一个很多 .vtk 和一个 .visit 索引文件,可以用 VisIt 或者 ParaView 打开(这个集群没有 GUI,所以可以把文件打包下载到本地,在本地安装 ParaView)。
也许?
将节点数设置为 1,然后在样例 2 上运行 clover_leaf,你可以可视化整个过程吗?把它加在报告中,你可以额外获得一些报告分数!
附录十六:赛中评测细分
最近更新:2025/07/26
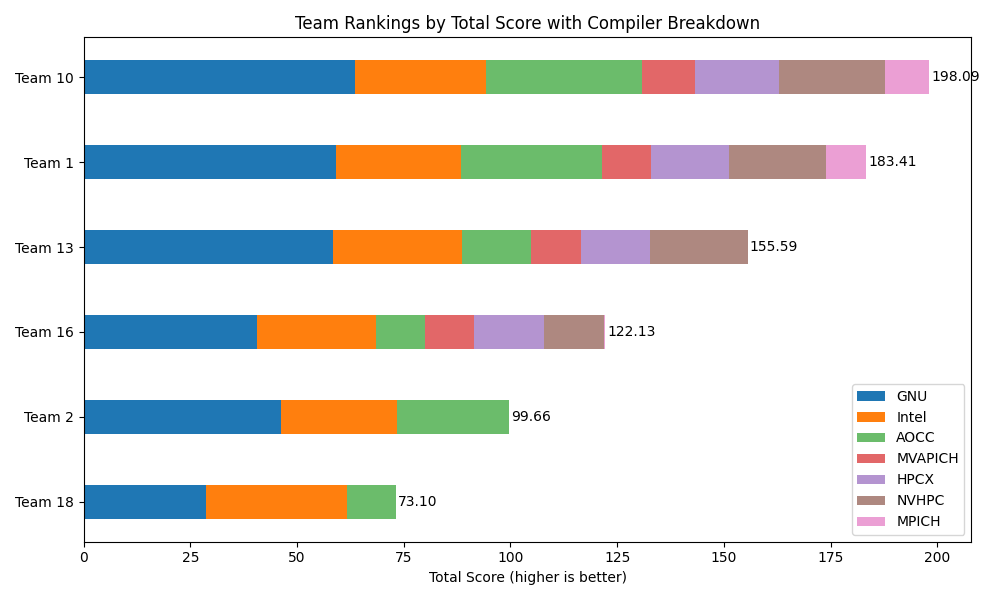
Team 1:
gnu: 28.242 (1st), 30.8958 (2nd)
intel: 14.5477 (1st), 14.671 (2nd)
mvapich: 5.6118 (1st), 5.8391 (2nd)
hpcx: 8.8744 (1st), 9.4203 (2nd)
nvhpc: 8.8181 (1st), 13.8711 (2nd)
aocc: 11.9489 (1st), 21.1257 (2nd)
mpich: 4.47 (1st), 5.0718 (2nd)
Total: 183.407700
Team 2:
gnu: 21.8903 (1st), 24.4057 (2nd)
intel: 13.7057 (1st), 13.4594 (2nd)
aocc: 9.4241 (1st), 16.7753 (2nd)
Total: 99.660500
Team 10:
gnu: 28.0527 (1st), 35.5456 (2nd)
intel: 14.108 (1st), 16.5567 (2nd)
aocc: 11.9635 (1st), 24.6572 (2nd)
hpcx: 8.669 (1st), 10.8491 (2nd)
mvapich: 5.6885 (1st), 6.725 (2nd)
nvhpc: 8.736 (1st), 16.0891 (2nd)
mpich: 4.4931 (1st), 5.9538 (2nd)
Total: 198.087300
Team 13:
gnu: 28.2441 (1st), 30.1137 (2nd)
intel: 15.6098 (1st), 14.6381 (2nd)
aocc: 6.1075 (1st), 10.0817 (2nd)
mvapich: 5.677 (1st), 5.9459 (2nd)
hpcx: 8.2679 (1st), 8.0847 (2nd)
nvhpc: 8.8166 (1st), 14.0031 (2nd)
Total: 155.590100
Team 16:
gnu: 19.3084 (1st), 21.2102 (2nd)
intel: 13.9461 (1st), 14.1191 (2nd)
aocc: 5.933 (1st), 5.5497 (2nd)
mvapich: 5.616 (1st), 5.7623 (2nd)
hpcx: 8.2547 (1st), 8.1137 (2nd)
nvhpc: 8.1878 (1st), 5.8531 (2nd)
mpich: 0.2361 (1st), 0.0362 (2nd)
Total: 122.126400
Team 18:
gnu: 14.1539 (1st), 14.5331 (2nd)
intel: 16.881 (1st), 16.0667 (2nd)
aocc: 5.9316 (1st), 5.5313 (2nd)
Total: 73.097600附录十七:报告要求(详细版)
比赛总成绩由两部分组成:一是自动脚本计算的性能分,二是评委人工评阅的报告分。两者完全独立,因此只追求跑分而忽视文档,同样会拉低最终排名。评委评分时更看重选手的思考过程与优化逻辑,而不仅是“跑得快”这一结果。
评委在阅读报告时,通常依次关注以下要素。
1 整体结构是否完整
正面示例
报告首页有自动生成的目录,点进去可以跳回相应章节;图表编号、引用都准确,附录还能迅速定位到关键代码行。
常见问题
全文就是一份超长 Markdown,没有目录也没有页码;图表编号混乱,评委想找你改动的循环只能靠全局搜索。
2 背景与动机是否交代清楚
正面示例
先用 VTune 热点视图展示 52 % 的时间耗在 update_halo,再说明是因为域分解导致缓存行反复失效,于是决定调整划分策略。
常见问题
开头只写一句“程序太慢,需要优化”,然后直接贴出向量化代码,但完全没解释为什么选这一步,也没证明那真的是瓶颈。
3 方法与实现是否有理有据
正面示例
每一步都遵循“现象、推理、实施、验证”:先给出 cache miss 统计,再讲 loop tiling 思路,接着贴关键 pragma,最后用 L2 带宽对比验证收益。
常见问题
把整段代码格式化重排,出现大量无关 diff;只说“我们做了适当调整”,既看不出改动,也没有量化效果。
4 实验设计是否严谨
正面示例
硬件规格、节点拓扑、核心数、线程绑定方式、环境变量都写清楚,所有测量在凌晨空闲时段重复五次并取中位数。
常见问题
只写“在服务器上测试”,既不说明 CPU 型号,也不交代线程绑定;不同网格尺寸混在一起比较,数据根本没法对照。
5 结果与分析是否到位
正面示例
用折线图展示基线到每步优化到最终版本的壁钟时间,并给出 IPC、缓存命中率等辅助曲线,解释第三步为何出现小幅回退。
常见问题
正文只有一句“最终加速 2.3×”,既没有中间过程,也没有图表;看不出 2.3× 到底来自哪一步,误差也无法判断。
6 可复现性是否充分
正面示例
项目根目录提供 README;脚本里的路径全部使用相对地址。
常见问题
在干净节点上根本跑不起来。
7 写作质量是否专业
正面示例
行文流畅,术语统一;所有图表都有标题、坐标轴单位和数据来源,正文引用时明确指出结论。
常见问题
正文夹杂口语,比如“嗨起来”“随便改改就行”;图里横轴没单位,纵轴写着“性能”却不知是秒还是 GFLOPS;错别字频繁,阅读体验很差。
示例
2.3 NUMA‑Aware Domain Decomposition
对基线版本进行 gprof 和 Intel VTune Hotspots 分析后(见图 2‑1),我们发现
update_halo占用 52.7 % 的壁钟时间,其中 86 % 的延迟来自跨 NUMA 节点的远程加载。考虑到 2‑D 网格在 X 方向上连续,而 Y 方向上跨 NUMA,我们将原先 “X 列优先” 的分区方式改为 “Y 列优先”,使相邻 halo 常驻同一 NUMA 域。代码层面仅需调整索引宏INDX(i,j)(见 Listing 2‑2,行 42‑45),并在 MPI 初始化阶段加入MPI_Cart_create的新维度映射。调整后重新运行 3 000 × 3 000 网格测试,单节点 L2 cache miss 率从 37.1 % 降至 8.4 %(表 2‑4);跨两节点时通信量减少 24 %,
update_halo壁钟时间缩短 18.3 %。整体应用端到端速度从 97.6 s 提升至 79.8 s(取 5 次中位数,σ = 0.4 s)。其余物理量(Volume、Mass、Kinetic Energy)与参考结果一致,误差低于 0.02 %。
为何好
段落先给量化瓶颈,再阐释方案、列出关键改动行号,最后用具体数据验证效果,逻辑闭环且术语精确。
优化 1:把东西搬一搬
我们感觉
update_halo跑得超慢,估计是内存不够爽,于是把分区方向调了个头。然后代码里随便改了几行,把INDX里 i j 反过来,再加了点 MPI 设置就 OK。跑完后果然快了,差不多提速两成吧,哈哈,图在下面(图忘记编号了)。顺带说一句,结果完全没问题,反正我们肉眼看差不多就行。
为何差
没有任何量化依据或准确数据,语言口语化且缺乏编号;“两成”“差不多”模糊不清,图表引用不可追踪,正确性也未给出验证方式。
推荐的报告章节
一份条理清晰的技术报告通常包括以下部分:封面(含队伍信息和实现版本)、摘要、问题定位、优化策略与实现、实验设置、结果与讨论、可复现指引、结论、参考文献、附录。若有失败或回退的尝试,也可放进附录,让评委了解你辩证的思考过程。
写作时容易踩的坑
不少队伍在以下细节上丢分:只贴最终数字却欠缺过程数据;在不同硬件上做对比却未声明;表格或图里的轴缺失单位;代码注释模糊,无法迅速看出改动点;报告写着 gcc 12,脚本实际调用 gcc 10;提前检查这些细节能避免低级失误。
附录十八:学习资源参考
编译选项
混合 OpenMP/MPI 编程
- 犹他大学 Hybrid MPI/OpenMP Programming 讲义
- MPI+OpenMP 快速指南(Stony Brook Seawulf FAQ)
- PRACE Hybrid CPU Programming with OpenMP and MPI
- 非常详细的教程,如果有时间的话强烈推荐学习。
- POP Webinar: Identifying performance bottlenecks in hybrid MPI + OpenMP software
- 介绍了一套基于跟踪数据的小集合指标的方法,说明如何判别常见瓶颈。
- SC13: Hybrid MPI/OpenMP Parallel Programming
- 非常详细的教程,涵盖高级混合并行优化技巧。
CloverLeaf 相关
- SC23 OpenMP Booth Talk: An evaluation of MPI+OpenMP on heterogeneous HPC systems
- 由布里斯托大学团队在 SC23 大会上发布的约20分钟报告视频,分析了混合 MPI+OpenMP 并行在 CPU 和 GPU 平台上的性能表现,包含了 CloverLeaf 等基准应用的实例。
- CloverLeaf on Intel Multi-Core CPUs: A Case Study in Write-Allocate Evasion
- 对 CloverLeaf 在英特尔新款多核 CPU 上的异常性能现象进行剖析。
- CloverLeaf 多模型实现仓库
- 包含 CloverLeaf 的多种并行编程模型实现。
- CloverLeaf: Preparing Hydrodynamics Codes for Exascale
