DiT 图像生成挑战
作者:Jaredan Xiao
INFO
🕷️ In every other universe Gwen Stacy falls for Spider-Man and in every other universe it doesn't end well.

序章:第617号宇宙
Gwen Stacy站在巨大的屏幕前,屏幕里面有数不清的小屏幕,每一个屏幕里都闪烁的不同的画面。看似每一个画面的色调、内容都不相同,但是似乎都发生在一个钟楼形态的建筑附近。「不——」在其中的一个画面中,一个女生从钟楼楼顶坠下,这是一个三维现实宇宙,她似乎是在某种攻击下丧失了平衡,开始坠落。发出声音的是画面中的男生,他从塔楼顶端开始不要命地向下俯冲,同时,他的右手手腕处似乎吐出一些白色细细的线。「嘭——」就在细线似乎连接其下坠女生的那一刻,女生的头同时和地面碰撞,产生了剧烈的声响。其他的画面里,紧接着都开始播放着相似的片段,都有关下坠,都有关蛛丝,都有关那个女生和那个男生,但似乎结局,每次都会以其中的一个人,抱着另一个人痛哭作为结局。
Gwen Stacy摁下了桌面的一个按键,屏幕切回了正常的工作界面,上面密布着各种检测的数据、指标,似乎还有一些进度条在计算着什么。「是时候下班了不是吗?」一个男生的声音从背后传来,那个男生正在脱下身上的有着蜘蛛丝网纹路的衣服,「今天还是没有什么进展吗?」
「还是太慢了」,Gwen Stacy摇摇头,「按这个速度下去,我们永远找不到那组参数的。」
那个男生最后把脸上的面罩脱下来,露出帅气的面庞。「别着急,我们还剩多少时间?」
「不多了」,Gwen Stacy摇摇头,「还是没有办法摆脱这个结局吗?Peter,我...我真的尽力了」
这里是第617宇宙,最开始的画面来自于第120703宇宙,仔细回想,画面里面的男生和女生和此时站在屏幕前的男生和女生都有几分相似。那画面里面,讲述的是在无数平行宇宙中已经发生了的Peter Parker和Gwen Stacy的故事。在每一个平行宇宙里,Peter Parker和Gwen Stacy都相爱了,但是在每一个平行宇宙中,他们都面临以一方的死亡告别彼此的结局。
在617宇宙中,Gwen Stacy成为了科学家,在大概两年前,她收到了来自另外一个平行宇宙的信号,告知她们这一悬挂在她与Peter之间的达摩克利斯之剑,并将其他已经经过这一时间节点的宇宙的画面同步传输给了617宇宙中的Gwen Stacy。那个信使是来自754号宇宙的Peter:「我没能拯救我的Gwen,但我想我们的进展是最大的,在所有的宇宙里面,你们离这个时间节点的距离观测来看是最远的,同时在这个宇宙里,你是智慧超凡的科学家,我相信你们有能力完成这一使命,帮我去找到那组参数和那个模型核,拜托了。」

有关Diffusion扩散模型
Diffusion是一种常用的生成手段,在617宇宙科技飞速发展的背景下,只要有足够多的信息,甚至可以预测不同平行宇宙的发展状态,前提只需要找到一组参数和一个模型核,通过反向过程,便可以基于给定模型核和坐标信息,逐渐生成某一事件的结果。模型核和不同的平行宇宙息息相关,只要找到了对应的对应的模型核,就可以定位到哪个平行宇宙中最可能摆脱这一看似既定的命运,还原那个宇宙中前一个关键节点的结果,或许就可以让所有平行宇宙中的Gwen和Peter摆脱告别的结局。
在得知了这一理论的可行性后,617宇宙的Gwen Stacy和Peter Parker开始不眠不休地尝试。每一个夜晚,他们都守在中央控制舱中,通过全息屏幕模拟数以万计的宇宙路径。他们尝试将从其他宇宙收集到的事件序列转化为数据点,反向推理可能的初始状态。现在的问题是,Diffusion的每一次推理过程都非常耗时,利用上分布式系统进行分布式推理,或许可以加快他们接近答案的时间。
扩散模型(Diffusion Models),特别是DDPM,是一类近年来在图像生成任务中表现非常优秀的生成模型,其核心思想是通过“正向加噪”和“反向去噪”的方式逐步构建出复杂的样本分布。
基本原理
1. 正向过程(Forward Process)
将真实数据
这里的
2. 反向过程(Reverse Process)
训练一个神经网络
实际训练中,目标是最小化预测噪声与真实噪声之间的误差:
3. 采样过程(Sampling)
从一个高斯噪声样本
最终得到一个看似从未存在,却极具现实感的样本。如果你对Diffusion模型的数学感兴趣,你可以参考这篇文章。
Scalable Diffusion Models with Transformers Github Repo Paper
在DiT以前,Diffusion模型主要使用U-Net结构作为主干网络,在图像生成任务上取得了很大的进展,使用U-Net作为主干网络的特点在于其包含一个下采样路径和一个对应的上采样路径,这种结构使得UNet在处理图像的时候可以更好地捕捉上下文信息、更有效地传递特征,并且改善梯度传递的速度。
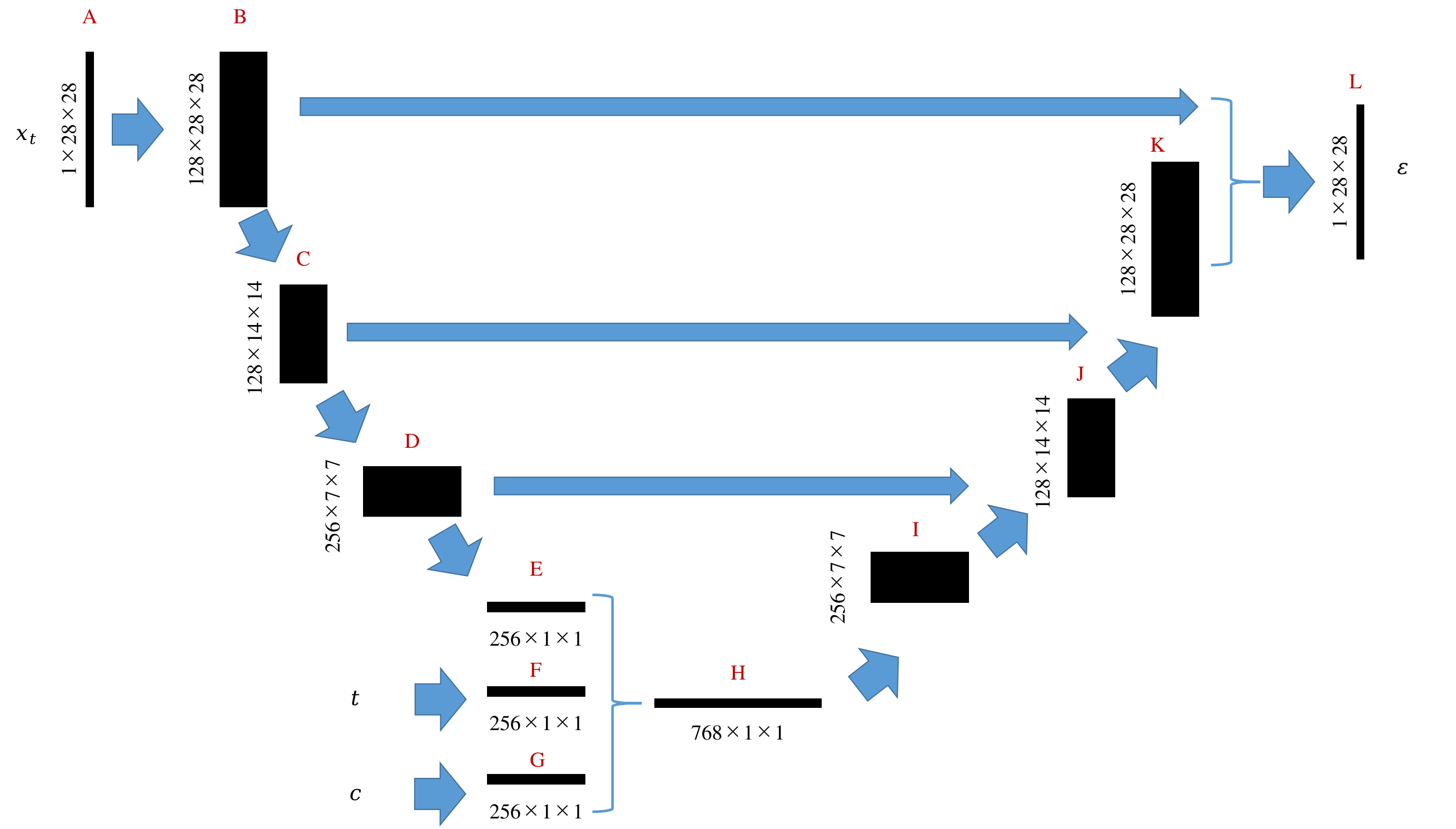
在著名的Transformer论文发表后, 很多常见的任务都从卷积神经网络(CNN)、残差神经网络(RNN)等慢慢被Transformer结构为主的神经网络替代,比较有名的就是Vision Transformer(ViT)。而在扩散模型中,一直没有很有效的基于Transformer模型的结构被提出,直到「Scalable Diffusion Models with Transformers」一文的出现。原因在于,最初的扩散模型都是针对图像的像素空间进行操作,像素空间具有非常强的空间局部性特征,卷积网络天然针对该任务有天然的适配性。Transformer结构的计算复杂度虽然是
DiT在针对问题上,做出了几项比较重要的改进,才得以在扩散模型中引入Transformer模型为架构的神经网络:
Patchify 输入
DiT 首先将输入图像分割为一系列 patch(类似 ViT),每个 patch 被展平成一个 token,输入到 Transformer 中。这种方式极大降低了 token 数量,使 Transformer 能够处理高分辨率图像。位置编码与时间步嵌入
除了常规的二维位置编码,DiT 还将扩散过程中的时间步(timestep)信息通过嵌入方式加入到每个 patch token 中,使模型能够感知当前的去噪阶段。高效的归一化与初始化策略
DiT 针对扩散模型的训练特点,采用了 LayerNorm、权重初始化等一系列优化策略,提升了训练稳定性和收敛速度。基于潜空间的建模
与传统的扩散模型直接在像素空间进行噪声添加和去噪不同,DiT 支持在潜空间(Latent Space)中进行扩散过程。具体来说,原始高维图像会先通过编码器(如 VAE 或其他降维网络)映射到一个更低维、更紧凑的潜在表示空间。扩散和去噪过程都在这个潜空间中进行,最后再通过解码器还原为高分辨率图像。
基于这几个优化之上,DiT得以利用上Transformer结构的优势来完成扩散的任务。 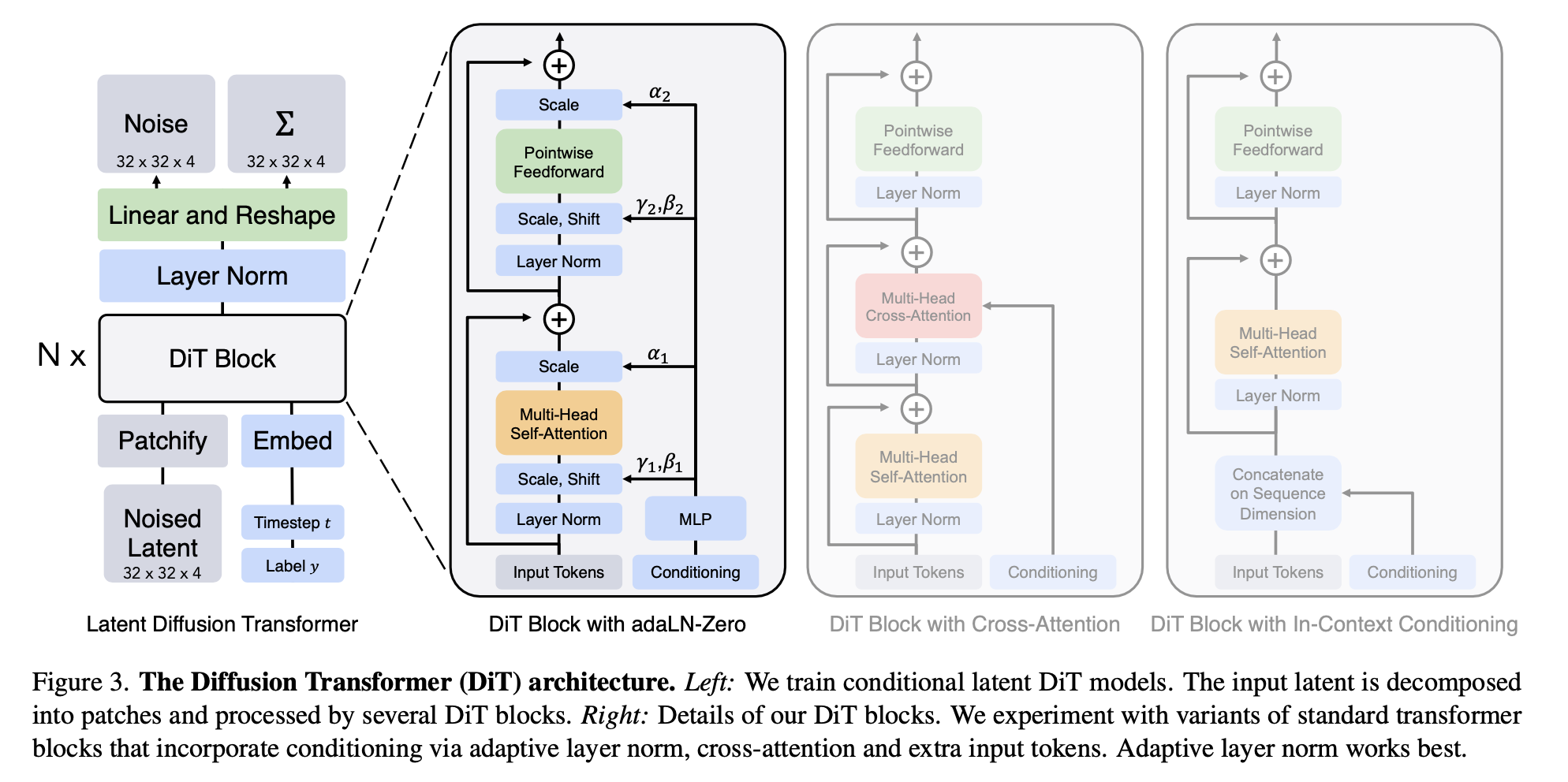 文章探索了多种Transformer结构的网络模型,如果感兴趣,可以从标题中的链接去阅读论文和代码。
文章探索了多种Transformer结构的网络模型,如果感兴趣,可以从标题中的链接去阅读论文和代码。
有关分布式推理
在此次DiT图像生成挑战中,我们主要将针对DiT模型中的Transformer结构进行优化,利用多卡加速推理过程中的Transformer结构的计算。下面的内容将会对语言模型中的常见分布式并行策略进行简要的介绍,需要提醒的是,在针对扩散模型的任务中,不一定每一个并行策略都会有很好的效果,选择合适的并行策略往往比盲目尝试更难实现的策略会带来更好的加速效果。
数据并行 (Data Parallelism)
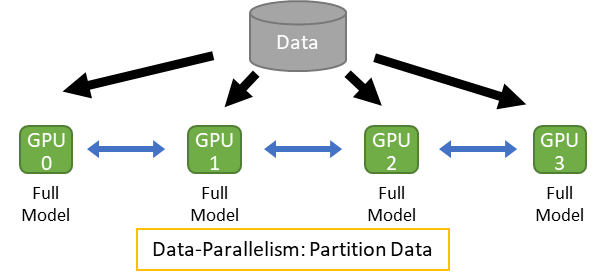
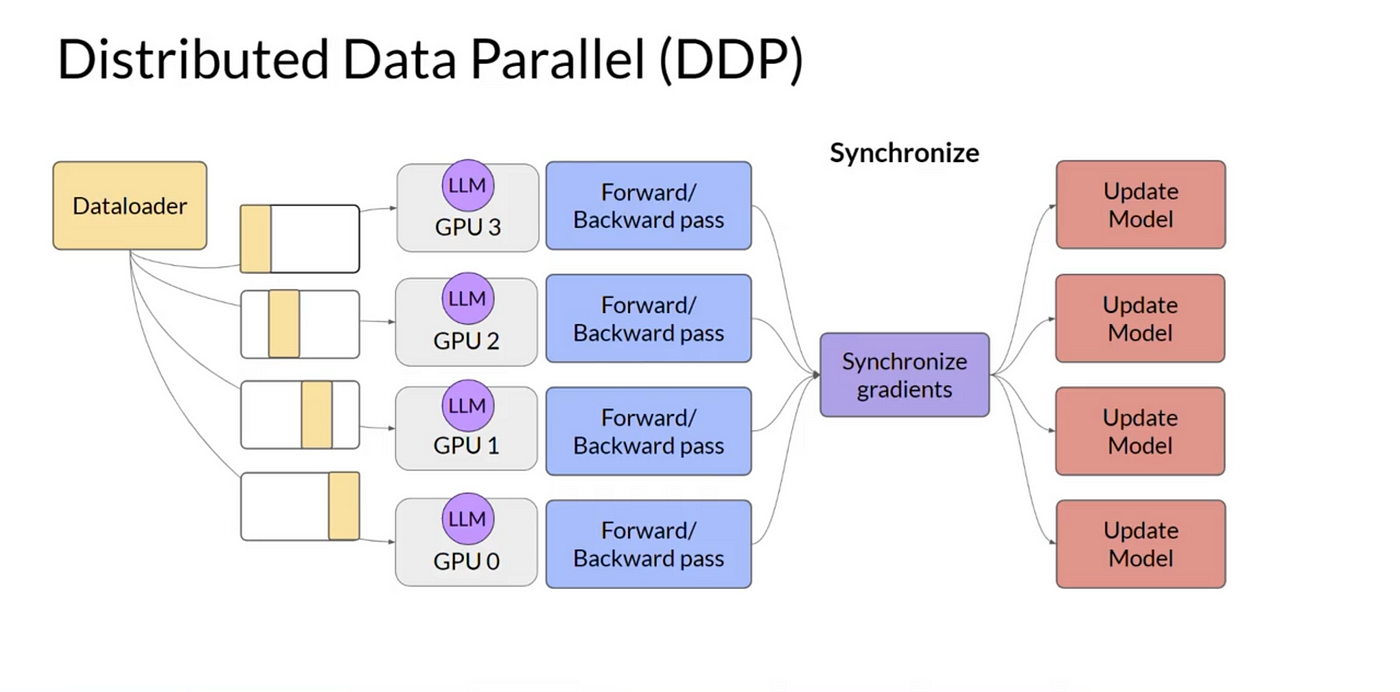
数据并行是一种将大型数据集分割到多个计算节点(如GPU)上进行并行处理的方法。每个节点保存完整的模型副本,独立处理分配给它的数据子集,并在训练过程中同步更新梯度。现代实现通常使用高效的All-reduce通信(如NVIDIA的NCCL库)来聚合梯度,替代传统的参数服务器方法,从而减少通信开销并提升效率。数据并行的核心优势是能够显著加速大规模数据集的训练,但需要确保梯度同步的高效性。
模型并行 (Model Parallelism)
模型并行通过将模型本身分割到不同设备上来解决单个设备内存不足的问题,主要包括以下两种方式:
- 流水线并行 (Pipeline Parallelism)
将模型按层水平分割,不同设备负责不同的层。通过将输入数据分成微批次(micro-batches)并重叠计算与通信,减少设备间的“气泡”(空闲时间)。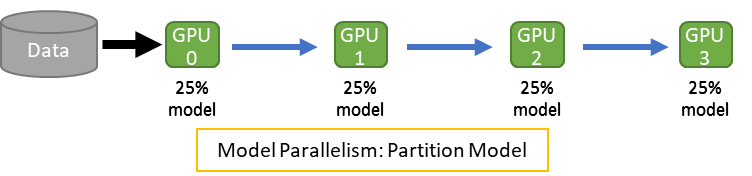 例如,GPipe框架通过这种方式实现了高效的分层并行。
例如,GPipe框架通过这种方式实现了高效的分层并行。 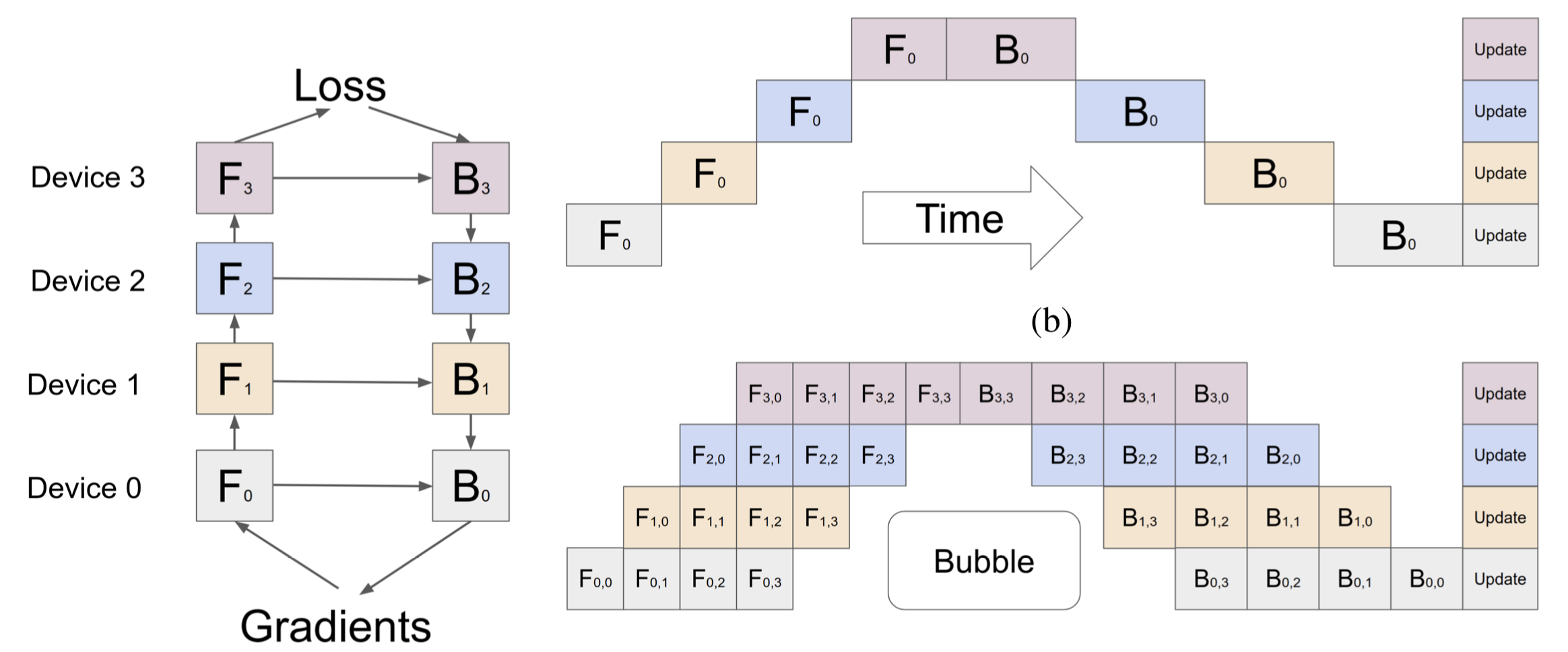
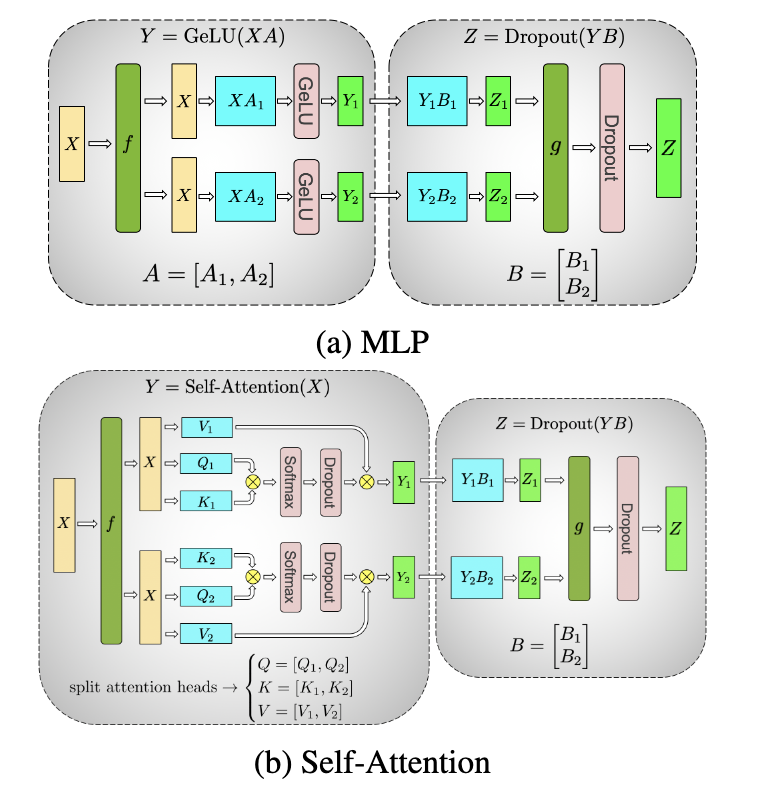
- 张量并行 (Tensor Parallelism) 将模型按运算垂直分割,例如将矩阵乘法或注意力头分布到多个设备上。每个设备处理部分计算,并通过All-reduce通信聚合结果(如Megatron-LM的实现)。这种方式适合参数量极大的模块(如Transformer层)
序列并行 (Sequence/Context Parallelism)
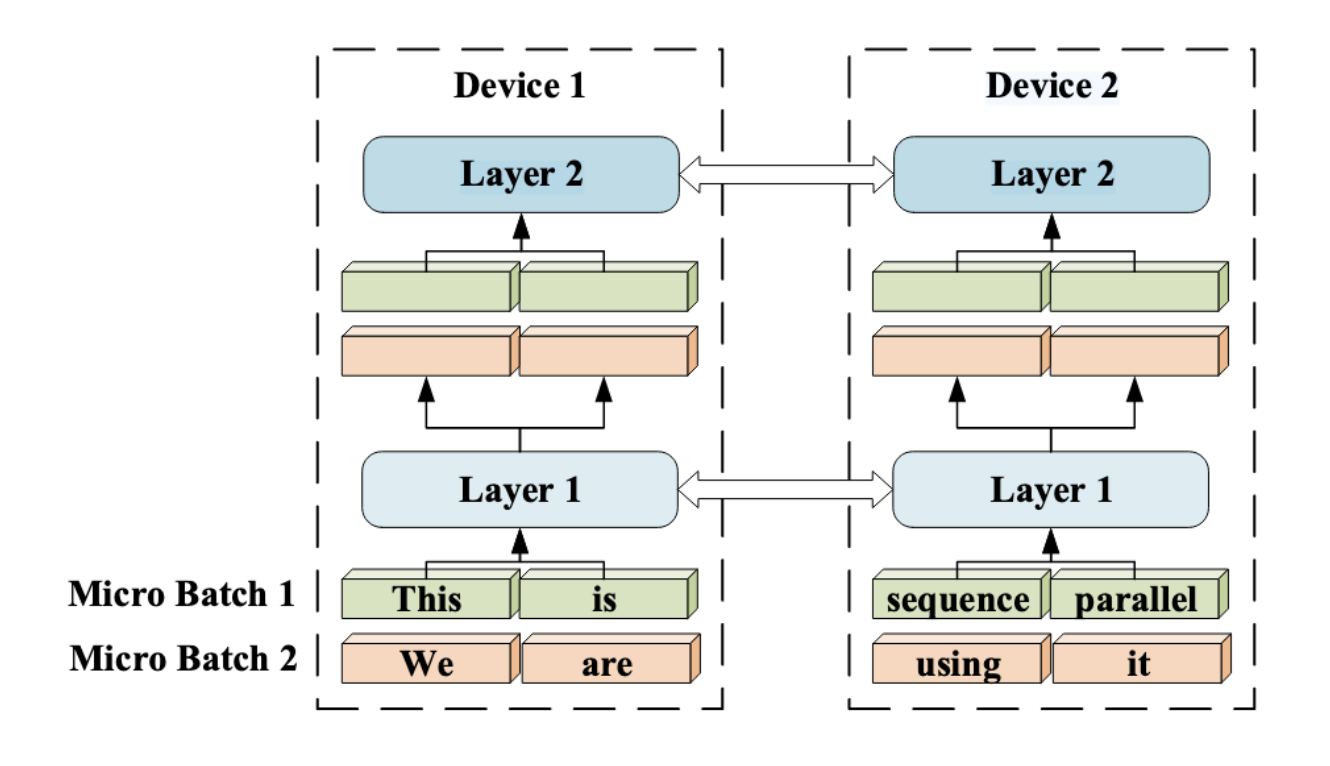
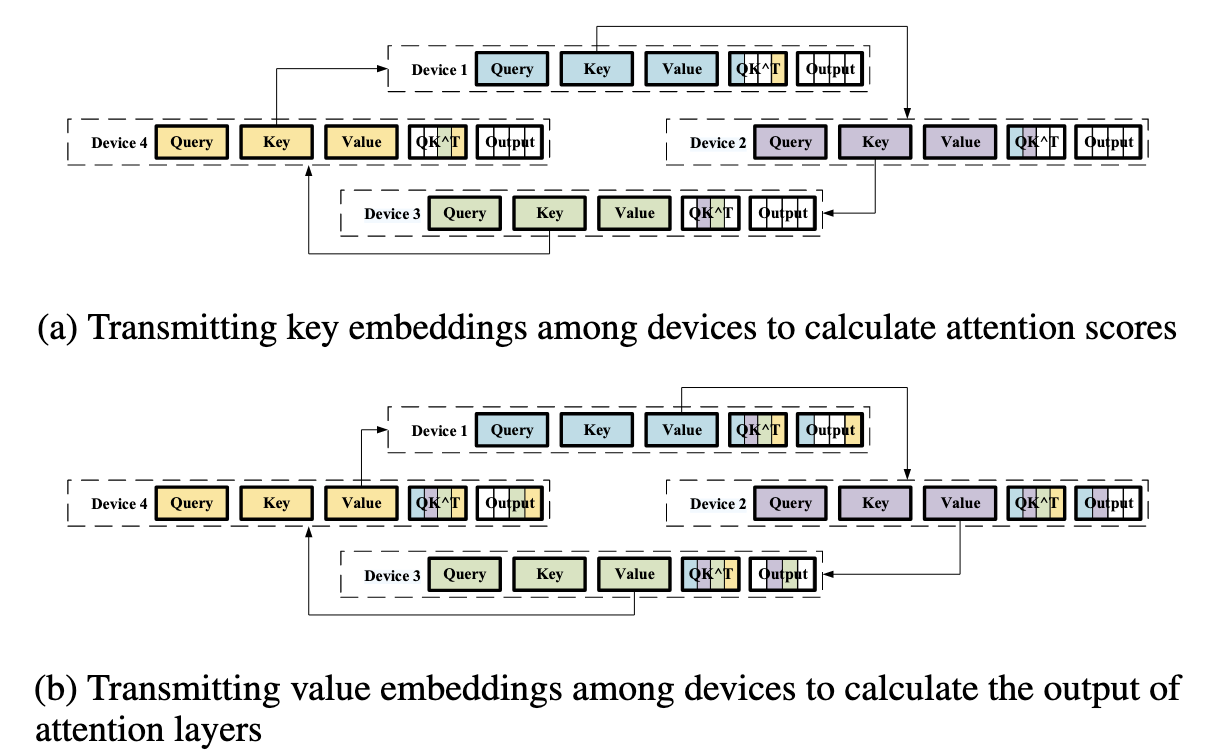
序列并行是针对长序列输入设计的并行方法,将输入序列分割成多个子序列,分配到不同设备处理。例如,在自注意力机制中,每个设备计算局部注意力结果,再通过通信(如Ring Attention)整合全局信息。这种方法突破了单设备对序列长度的限制,适用于自然语言处理中的长文本任务。
在这些基础的分布式范式上,仍然有很多高阶的分布式技巧比如ZeRO、3D并行被提出,利用DiT性质的并行策略比如PipeFusion,USP等范式也被提出,如果你对此感兴趣,可以参考这个博客Ultra-Scale Playbook。这个博客将带你详细进入分布式训练和推理的奇妙世界。
题目说明
Diffusion扩散模型不仅仅在文生图任务中应用广泛,在目前工业大模型中,以Transformer作为骨架网络的Diffusion扩散模型也得到广泛的应用,比如在蛋白质结构预测的AlphaFold3、在VLM(Vision-Language-Model)任务中的
作业脚本示例
#!/bin/bash
#SBATCH --job-name=dit_inference
#SBATCH --output=dit_inference.out
#SBATCH --error=dit_inference.err
#SBATCH -N=1
#SBATCH -c=4
#SBATCH --mem=128M
#SBATCH --gres=gpu:v100:4
#SBATCH --time=01:00:00
#SBATCH --partition=8v100-32
source ~/.bashrc
conda activate DiT
cd /path/to/DiT-SUSTCSC
python sample.py竞赛规则
目标任务
请帮助 Gwen 和 Peter 优化并加速 DiT 模型的推理速度。你需要针对 DiT 模型的 Transformer 结构,设计并实现高效的推理优化方案。赛题代码仓库:https://github.com/Jaredanwolfgang/DiT-SUSTCSC代码规范
- 可以对代码进行任意位置的修改
- 需要提供文档说明所做出的代码更改内容
硬件与环境
- 所有评测将在指定的集群环境和硬件平台上进行
- 允许自定义环境配置(如 Dockerfile),但需保证可复现性
生成质量验证
- 由于扩散模型去噪过程中有种子随机性,因此生成质量检测指标将进行修改
- 请通过
sample.py生成8组 8个标签对应的图片至output文件夹中 - 请使用
evaluate.py评测Baseline图片和代码改动之后生成图片文件夹的output/sample_{id}.png,你会看到Metrics的生成 - 最终Pixel-wise Mean Absolute Difference
, LPIPS的分数需要满足 ,SSIM的分数需要满足 ,PSNR的分数需要满足 - 由于生成质量较难评估,只要生成质量能够基本反应类别即可
- 组委会有权要求参赛队伍进一步解释优化方案,并在不同参数或硬件下复测
评测
- 评测模型为:VAE
stabilityai/sd-vae-ft-ema+ DiTDiT-XL-2-512x512 - 评测平台:
ssc-gpu队列中 1机4卡(NVIDIA V100 GPU (32GB)) - 最终得分分为两个部分:性能分 + 报告分,占比为性能占比
报告占比为 - 报告分:报告的具体评价标准请参考提交指南
- 性能分:性能分得分请参考以下标准
- Baseline时间为360s (
batch_size大小为8的Baseline生成速度) - 评分公式:
- Baseline时间为360s (
提交指南
代码提交「集群提交」
请将至少包含了一下目录的DiT-SUSTC文件提交至对应的集群目录下:
.
├── README.md
├── diffusion
│ ├── __init__.py
│ ├── diffusion_utils.py
│ ├── gaussian_diffusion.py
│ ├── respace.py
│ └── timestep_sampler.py
├── evaluate.py
├── models.py
├── output # Only contains your final result
│ ├── sample_0.png
│ ├── sample_1.png
│ ├── sample_2.png
│ └── ...
├── pretrained_models
│ ├── DiT-XL-2-512x512.pt
│ ├── download.py
│ └── sd-vae-ft-ema
├── requirements.txt
├── sample.py
└── sample_ddp.py除此之外请包涵两个文档:
- 代码运行指南:主要是相比Baseline是否添加的新增的库文件
- 优化说明:简要指出主要的代码修改部分,以及尝试的优化方案
报告提交「邮件提交」
优化报告:内容包括但不限于:
- 单卡 Baseline 结果
- 单卡 Profile 结果及性能瓶颈分析
- 单卡优化方案与结果(如更换更快的矩阵计算库,算子融合等)
- 多卡方案设计(基于 Ultra-Scale PlayBook,分析适合 DiT 的并行策略)
- 多卡优化结果(使用数据并行/模型并行/序列并行等方式)
- 关键优化点、创新性说明、遇到的问题与解决方法
报告评分标准
| 内容 | 比例 |
|---|---|
| 1. 单卡 Baseline 结果 | 10% |
| 2. 单卡 Profile 结果,并分析性能瓶颈 | 20% |
| 3. 单卡优化结果(更换更快的矩阵计算库、重叠通信流等方式) | 20% |
| 4. 多卡方案设计(阅读 Ultra-Scale PlayBook,分析适合的并行策略) | 25% |
| 5. 多卡优化结果(使用数据并行/模型并行/序列并行等方式) | 25% |
说明与致谢
本赛题为南方科技大学 2025 年超算比赛进阶赛道DiT图像生成挑战赛题。本赛题所有资源遵循 CC BY-NC-SA 4.0 协议,允许非商业性使用与修改。同时,GitHub 仓库 已开放讨论区,欢迎大家在此讨论与交流。如有任何问题,请提出 issue 或联系 xiaoyc2022@mail.sustech.edu.cn. 出题人:Jaredan Xiao.
参考资料
- 扩散模型U-Net可视化理解
- Diffusion模型为何倾向于钟爱U-net结构?
- 扩散模型(Diffusion Model)详解:直观理解、数学原理、PyTorch 实现
- Peebles, W., & Xie, S. (2023). Scalable Diffusion Models with Transformers (No. arXiv:2212.09748). arXiv. https://doi.org/10.48550/arXiv.2212.09748
- Fang, J., & Zhao, S. (2024). USP: A Unified Sequence Parallelism Approach for Long Context Generative AI (No. arXiv:2405.07719). arXiv. https://doi.org/10.48550/arXiv.2405.07719
- Wang, J., Fang, J., Li, A., & Yang, P. (2024). PipeFusion: Displaced Patch Pipeline Parallelism for Inference of Diffusion Transformer Models (No. arXiv:2405.14430). arXiv. https://doi.org/10.48550/arXiv.2405.14430
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models (No. arXiv:2006.11239). arXiv. http://arxiv.org/abs/2006.11239
- Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, D., Chen, M., Lee, H., Ngiam, J., Le, Q. V., Wu, Y., & Chen, zhifeng. (2019). GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. Advances in Neural Information Processing Systems, 32. https://proceedings.neurips.cc/paper/2019/hash/093f65e080a295f8076b1c5722a46aa2-Abstract.html
- Li, S., Xue, F., Baranwal, C., Li, Y., & You, Y. (2022). Sequence Parallelism: Long Sequence Training from System Perspective (No. arXiv:2105.13120). arXiv. http://arxiv.org/abs/2105.13120
- Narayanan, D., Shoeybi, M., Casper, J., LeGresley, P., Patwary, M., Korthikanti, V., Vainbrand, D., Kashinkunti, P., Bernauer, J., Catanzaro, B., Phanishayee, A., & Zaharia, M. (2021). Efficient large-scale language model training on GPU clusters using megatron-LM. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 1–15. https://doi.org/10.1145/3458817.3476209